
对象已经死亡?
如何判断一个类是无用的类
方法区主要回收的是无用的类,那么如何判断一个类是无用的类的呢?
判定一个常量是否是“废弃常量”比较简单,而要判定一个类是否是“无用的类”的条件则相对苛刻许多。类需要同时满足下面 3 个条件才能算是 “无用的类” :
- 该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
- 加载该类的
ClassLoader已经被回收。 - 该类对应的
java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
虚拟机可以对满足上述 3 个条件的无用类进行回收,这里说的仅仅是“可以”,而并不是和对象一样不使用了就会必然被回收。
JVM内存划分
类加载过程
过程:加载、验证、准备、解析、初始化
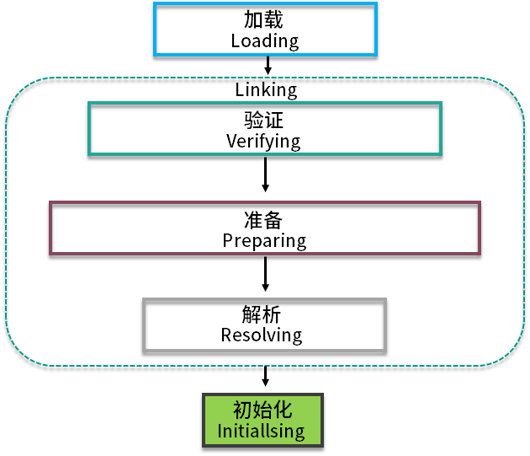
类加载过程分为三个阶段:Load、Link和Init,即加载、链接、初始化
- 第一步,Load阶段读取类文件产生二进制流,并转化为特定的数据结构,初步校验cafe babe魔法数、常量池、文件长度、是否有父类等,然后创建对应类的
java.lang.Class实例 - 第二步,Link阶段包括验证、准备、解析三个步骤。验证是更详细的校验,比如final是否合规、类型是否正确、静态变量是否合理等;准备阶段是为静态变量分配内存,并设定默认值,解析类和方法确保类与类之间的相互引用正确性,完成内存结构布局。
- 第三步,Init阶段执行雷构造器<clinit>方法,如果赋值运算是通过其他类的静态方法来完成的,那么会马上解析另外一个类,在虚拟机栈中执行完毕后通过返回值进行赋值。
双亲委派机制
什么是双亲委派机制
首先,我们知道,虚拟机在加载类的过程中需要使用类加载器进行加载,而在Java中,类加载器有很多,那么当JVM想要加载一个.class文件的时候,到底应该由哪个类加载器加载呢?
这就不得不提到”双亲委派机制”。
首先,我们需要知道的是,Java语言系统中支持以下4种类加载器:
- Bootstrap ClassLoader 启动类加载器
- Extention ClassLoader 标准扩展类加载器
- Application ClassLoader 应用类加载器
- User ClassLoader 用户自定义类加载器
这四种类加载器之间,是存在着一种层次关系的,如下图
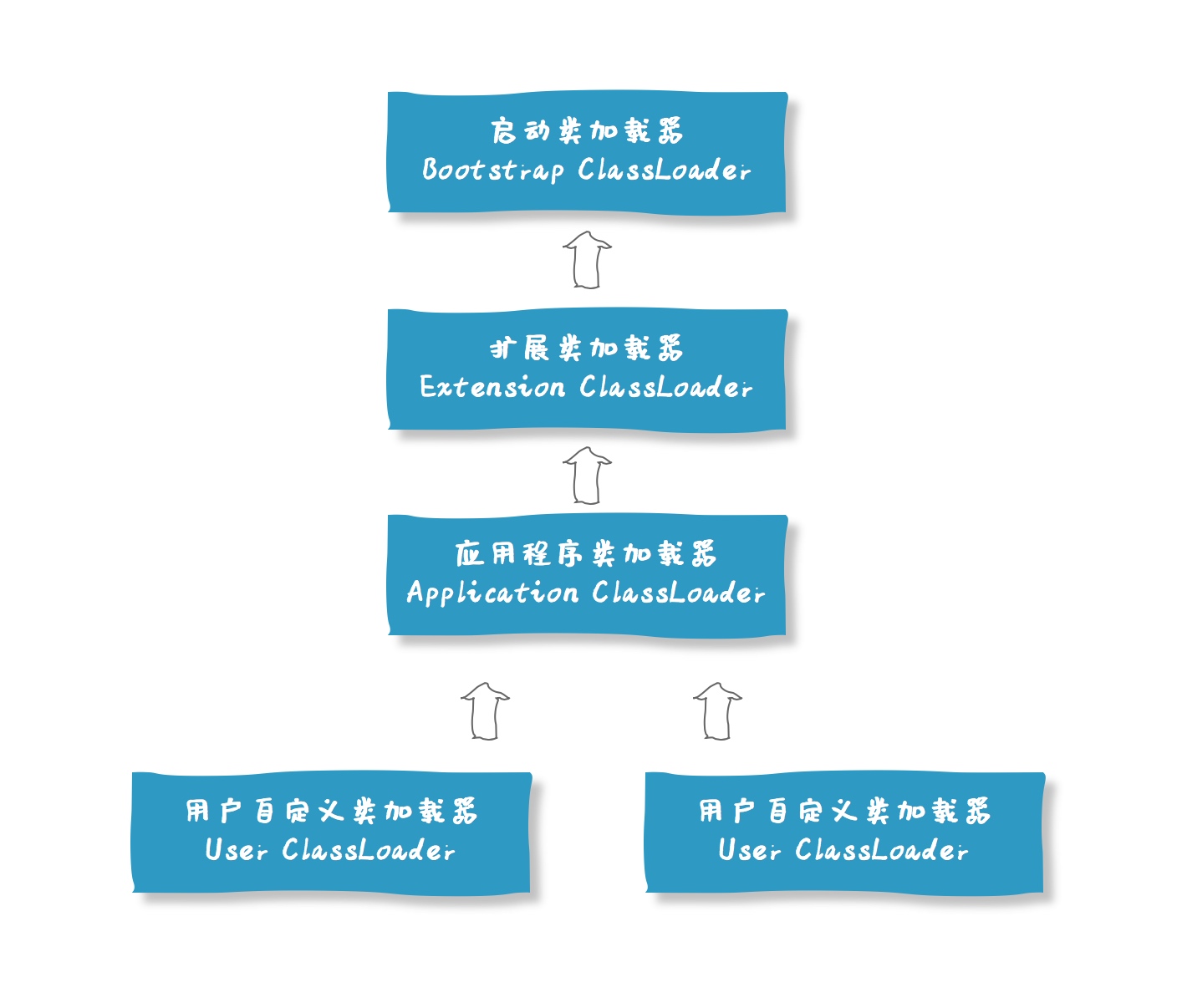
一般认为上一层加载器是下一层加载器的父加载器,那么,除了BootstrapClassLoader之外,所有的加载器都是有父加载器的。
那么,所谓的双亲委派机制,指的就是:当一个类加载器收到了类加载的请求的时候,他不会直接去加载指定的类,而是把这个请求委托给自己的父加载器去加载。只有父加载器无法加载这个类的时候,才会由当前这个加载器来负责类的加载。
那么,什么情况下父加载器会无法加载某一个类呢?
其实,Java中提供的这四种类型的加载器,是有各自的职责的:
- Bootstrap ClassLoader ,主要负责加载Java核心类库,%JRE_HOME%\lib下的rt.jar、resources.jar、charsets.jar和class等。
- Extention ClassLoader,主要负责加载目录%JRE_HOME%\lib\ext目录下的jar包和class文件。
- Application ClassLoader ,主要负责加载当前应用的classpath下的所有类
- User ClassLoader , 用户自定义的类加载器,可加载指定路径的class文件
那么也就是说,一个用户自定义的类,如com.hollis.ClassHollis 是无论如何也不会被Bootstrap和Extention加载器加载的(-Xbootclasspath参数是否可以使得自定义类被bootstrap加载?)。
JVM垃圾回收
垃圾回收器
JDK8-CMS:(关注最短垃圾回收停顿时间)
CMS回收器(Concurrent Mark Sweep Collector)是回收停顿时间比较短,目前比较常用的垃圾回收器。它通过初始标记(Initial Mark)、并发标记(Concurrent Mark)、重新标记(Remark)、并发清除(Concurrent Sweep)四个步骤完成垃圾回收工作。第1、3步的初始标记和重新标记阶段依然会引发STW。2、4步可以和应用程序并发执行。CMS采用“标记 - 清除算法”,因此产生大量的空间碎片。可以通过-XX:+UseCMSCompactAtFullCollection参数,强制JVM在FGC完成后对老年代进行压缩,执行一次空间碎片整理,但是会引发STW。为了减少STW次数,CMS还可以通过配置-XX:+CMSFullGCsBeforeCompaction=n参数,在执行了n次FGC后,JVM再在老年代执行空间碎片整理。
JDK9-G1:(精准控制停顿时间,避免垃圾碎片)
G1(Garbage-First Garbage Collector)垃圾回收器。
是⼀款⾯向服务器的垃圾收集器,主要针对配备多颗处理器及⼤容量内存的机器.以极⾼概率满⾜GC停顿时
间要求的同时,还具备⾼吞吐量性能特征;相比与 CMS 收集器,G1 收集器两个最突出的改进是:
【1】基于标记-整理算法,不产生内存碎片。
【2】可以非常精确控制停顿时间,在不牺牲吞吐量前提下,实现低停顿垃圾回收。
G1 收集器避免全区域垃圾收集,它把堆内存划分为大小固定的几个独立区域,并且跟踪这些区域的垃圾
收集进度,同时在后台维护一个优先级列表,每次根据所允许的收集时间,优先回收垃圾最多的区域。区域划
分和优先级区域回收机制,确保 G1 收集器可以在有限时间获得最高的垃圾收集效率。
初始标记:Stop The World,仅使用一条初始标记线程对GC Roots关联的对象进行标记
并发标记:使用一条标记线程与用户线程并发执行。此过程进行可达性分析,速度很慢
最终标记:Stop The World,使用多条标记线程并发执行
筛选回收:回收废弃对象,此时也要 Stop The World,并使用多条筛选回收线程并发执行
G1垃圾回收期原理
TODO
ZGC
2022年6月5日TODO(作为亮点)
如何配置垃圾收集器
- 首先是内存大小问题,基本上每一个内存区域我都会设置一个上限,来避免溢出问题,比如元空间。
- 通常,堆空间我会设置成操作系统的 2/3,超过 8GB 的堆,优先选用 G1
- 然后我会对 JVM 进行初步优化,比如根据老年代的对象提升速度,来调整年轻代和老年代之间的比例
- 依据系统容量、访问延迟、吞吐量等进行专项优化,我们的服务是高并发的,对 STW 的时间敏感
- 我会通过记录详细的 GC 日志,来找到这个瓶颈点,借用 GCeasy 这样的日志分析工具,定位问题
GC触发条件
MinorGC触发条件
当Eden区满时触发MinorGC
FullGC触发条件
- 调用System.gc时,系统建议执行FullGC,但是不必然执行
- 老年代空间不足
- 方法区空间不足(jdk8之前)
- 通过MinorGC后进入老年代的平均大小大于老年代的可用内存
- 由Eden区、FromSpace向ToSpace区复制时,对象大小大于ToSpace可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小
JVM调优
JVM优化的思路
1、一般来说,当survivor区不够大或者占用量达到50%,就会把一些对象放到老年区。通过设置合理的eden区,survivor区及使用率,可以将年轻对象保存在年轻代,从而避免full GC,使用-Xmn设置年轻代的大小
2、对于占用内存比较多的大对象,一般会选择在老年代分配内存。如果在年轻代给大对象分配内存,年轻代内存不够了,就要在eden区移动大量对象到老年代,然后这些移动的对象可能很快消亡,因此导致full GC。通过设置参数:-XX:PetenureSizeThreshold=1000000,单位为B,标明对象大小超过1M时,在老年代(tenured)分配内存空间。
3、一般情况下,年轻对象放在eden区,当第一次GC后,如果对象还存活,放到survivor区,此后,每GC一次,年龄增加1,当对象的年龄达到阈值,就被放到tenured老年区。这个阈值可以同构-XX:MaxTenuringThreshold设置。如果想让对象留在年轻代,可以设置比较大的阈值。
4、设置最小堆和最大堆:-Xmx和-Xms稳定的堆大小堆垃圾回收是有利的,获得一个稳定的堆大小的方法是设置-Xms和-Xmx的值一样,即最大堆和最小堆一样,如果这样子设置,系统在运行时堆大小理论上是恒定的,稳定的堆空间可以减少GC次数,因此,很多服务端都会将这两个参数设置为一样的数值。稳定的堆大小虽然减少GC次数,但是增加每次GC的时间,因为每次GC要把堆的大小维持在一个区间内。
5、一个不稳定的堆并非毫无用处。在系统不需要使用大内存的时候,压缩堆空间,使得GC每次应对一个较小的堆空间,加快单次GC次数。基于这种考虑,JVM提供两个参数,用于压缩和扩展堆空间。
(1)-XX:MinHeapFreeRatio 参数用于设置堆空间的最小空闲比率。默认值是40,当堆空间的空闲内存比率小于40,JVM便会扩展堆空间
(2)-XX:MaxHeapFreeRatio 参数用于设置堆空间的最大空闲比率。默认值是70, 当堆空间的空闲内存比率大于70,JVM便会压缩堆空间。
(3)当-Xmx和-Xmx相等时,上面两个参数无效
6、通过增大吞吐量提高系统性能,可以通过设置并行垃圾回收收集器。
(1)-XX:+UseParallelGC:年轻代使用并行垃圾回收收集器。这是一个关注吞吐量的收集器,可以尽可能的减少垃圾回收时间。
(2)-XX:+UseParallelOldGC:设置老年代使用并行垃圾回收收集器。
7、尝试使用大的内存分页:使用大的内存分页增加CPU的内存寻址能力,从而系统的性能。-XX:+LargePageSizeInBytes 设置内存页的大小
8、使用非占用的垃圾收集器。-XX:+UseConcMarkSweepGC老年代使用CMS收集器降低停顿。
9、-XXSurvivorRatio=3,表示年轻代中的分配比率:survivor:eden = 2:3
10、JVM性能调优的工具:
(1)jps(Java Process Status):输出JVM中运行的进程状态信息(现在一般使用jconsole)
(2)jstack:查看java进程内线程的堆栈信息。
(3)jmap:用于生成堆转存快照
(4)jhat:用于分析jmap生成的堆转存快照(一般不推荐使用,而是使用Ecplise Memory Analyzer)
(3)jstat是JVM统计监测工具。可以用来显示垃圾回收信息、类加载信息、新生代统计信息等。
(4)VisualVM:故障处理工具
生产环境JVM调优具体步骤
1.监控GC的状态
使用各种JVM工具,查看当前日志,分析当前JVM参数设置,并且分析当前堆内存快照和gc日志,根据实际的各区域内存划分和GC执行时间,觉得是否进行优化。举一个例子,系统崩溃前的一些现象:每次垃圾回收的时间越来越长,由之前的10ms延长到50ms左右,FullGC的时间也由之前的0.5s延长到4、5s,FullGC的次数越来越多,最频繁时隔不到1分钟就进行一次FullGC,老年代的内存越来越大并且每次FGC后老年代没有内存释放,之后系统会无法响应新的数据,逐渐到达OutMemoryError的临界值,这个时候就需要分析JVM内存快照dump。
2.生成堆的dump文件
通过JMX的MBean生成当前的Heap信息,大小为一个3G(整个堆得大小)的hprof文件,如果没有启动JMX可以通过Java的jmap命令来生成改文件。
3.分析dump文件
打开这个3G的堆信息文件,显然一般的Windows系统没有这么大的内存,必须借助高配置的Linux,几种工具打开该文件:Visual VM、IBM HeadpAnalyzer、JDK自带的Hprof工具、Mat(Eclipse专门的静态内存分析工具)推荐使用。Tips:文件太大,建议使用Eclipse专门的静态内存工具Mat打开分析。
4.分析结果,判断是否需要优化
如果各项参数设置合理,系统没有超时日志出现,GC频率不高,GC耗时不高,那么没有必要进行GC优化,如果GC时间超过1-3s,或者频繁GC,则必须优化。注意: 如果满足下面的指标,则一般不需要进行 GC 优化:
- MinorGC 执行时间不到50ms;
- Minor GC 执行不频繁,约10秒一次;
- Full GC 执行时间不到1s;
- Full GC 执行频率不算频繁,不低于10分钟1次。
5.调整GC类型和内存分配
如果内存分配 过大或过小,或者采用的GC收集器比较慢,则应该优先调整这些参数,并且先找1台或几台机器进行beta,然后比较优化过的机器和没有优化的机器的性能对比,并有针对性的做出最后选择。
6.不断的分析和调整
通过不断的试验和试错,分析并找出最合适的参数,如果找到了最合适的参数,则将这些参数应用到所有服务器。
一般遇到问题就是打出当时的线程信息生成dump然后查异常代码。
附:JVM 性能调优监控工具 jps、jstack、jmap、jhat、jstat、hprof 使用详解

