
递归
395. 至少有K个重复字符的最长子串
给你一个字符串 s 和一个整数 k ,请你找出 s 中的最长子串, 要求该子串中的每一字符出现次数都不少于 k 。返回这一子串的长度。
示例 1:
1 | 输入:s = "aaabb", k = 3 |
示例 2:
1 | 输入:s = "ababbc", k = 2 |
提示:
1 <= s.length <= 10^4s仅由小写英文字母组成1 <= k <= 10^5
解题思路
本题要求的一个最长的子字符串的长度,该子字符串中每个字符出现的次数都最少为 kk。
求最长子字符串/区间的这类题一般可以用滑动窗口来做,但是本题滑动窗口的代码不好写,我改用递归。也借本题来帮助大家理解递归。
- 重点:我们在调用递归函数的时候,把递归函数当做普通函数(黑箱)来调用,即明白该函数的输入输出是什么,而不用管此函数内部在做什么。
下面是详细讲解。
- 递归最基本的是记住递归函数的含义(务必牢记函数定义):本题的
longestSubstring(s, k)函数表示的就是题意,即求一个最长的子字符串的长度,该子字符串中每个字符出现的次数都最少为 k。函数入参 s 是表示源字符串;k 是限制条件,即子字符串中每个字符最少出现的次数;函数返回结果是满足题意的最长子字符串长度。 - 递归的终止条件(能直接写出的最简单 case):如果字符串 s 的长度少于 k,那么一定不存在满足题意的子字符串,返回 0;
- 调用递归(重点):如果一个字符 c 在 s 中出现的次数少于 k 次,那么 s 中所有的包含 c 的子字符串都不能满足题意。所以,应该在 s 的所有不包含 c 的子字符串中继续寻找结果:把 s 按照 c 分割(分割后每个子串都不包含 c),得到很多子字符串 t;下一步要求 t作为源字符串的时候,它的最长的满足题意的子字符串长度(到现在为止,我们把大问题分割为了小问题(s → t))。此时我们发现,恰好已经定义了函数
longestSubstring(s, k)就是来解决这个问题的!所以直接把longestSubstring(s, k)函数拿来用,于是形成了递归。 - 未进入递归时的返回结果:如果 s 中的每个字符出现的次数都大于 k 次,那么 s 就是我们要求的字符串,直接返回该字符串的长度。
总之,通过上面的分析,我们看出了:我们不是为了递归而递归。而是因为我们把大问题拆解成了小问题,恰好有函数可以解决小问题,所以直接用这个函数。由于这个函数正好是本身,所以我们把此现象叫做递归。小问题是原因,递归是结果。而递归函数到底怎么一层层展开与终止的,不要用大脑去想,这是计算机干的事。我们只用把递归函数当做一个能解决问题的黑箱就够了,把更多的注意力放在拆解子问题、递归终止条件、递归函数的正确性上来。
代码
1 | class Solution { |
82. 删除排序链表中的重复元素 II
存在一个按升序排列的链表,给你这个链表的头节点 head ,请你删除链表中所有存在数字重复情况的节点,只保留原始链表中 没有重复出现 的数字。
返回同样按升序排列的结果链表。
示例 1:
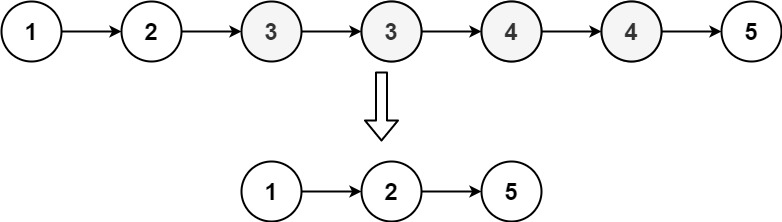
1 | 输入:head = [1,2,3,3,4,4,5] |
示例 2:
1 | 输入:head = [1,1,1,2,3] |
提示:
- 链表中节点数目在范围
[0, 300]内 -100 <= Node.val <= 100- 题目数据保证链表已经按升序排列
解题思路
题意:在一个有序链表中,如果一个节点的值出现不止一次,那么把这个节点删除掉。
重点:有序链表,所以,一个节点的值出现不止一次,那么它们必相邻。
1. 递归函数定义
递归最基本的是要明白递归函数的定义! 我反复强调过这一点。
递归函数直接使用题目给出的函数 deleteDuplicates(head) ,它的含义是 删除以 head 作为开头的有序链表中,值出现重复的节点。
2. 递归终止条件
终止条件就是能想到的基本的、不用继续递归处理的case。
- 如果
head为空,那么肯定没有值出现重复的节点,直接返回 head; - 如果
head.next为空,那么说明链表中只有一个节点,也没有值出现重复的节点,也直接返回 head。
3. 递归调用
什么时候需要递归呢?我们想一下这两种情况:
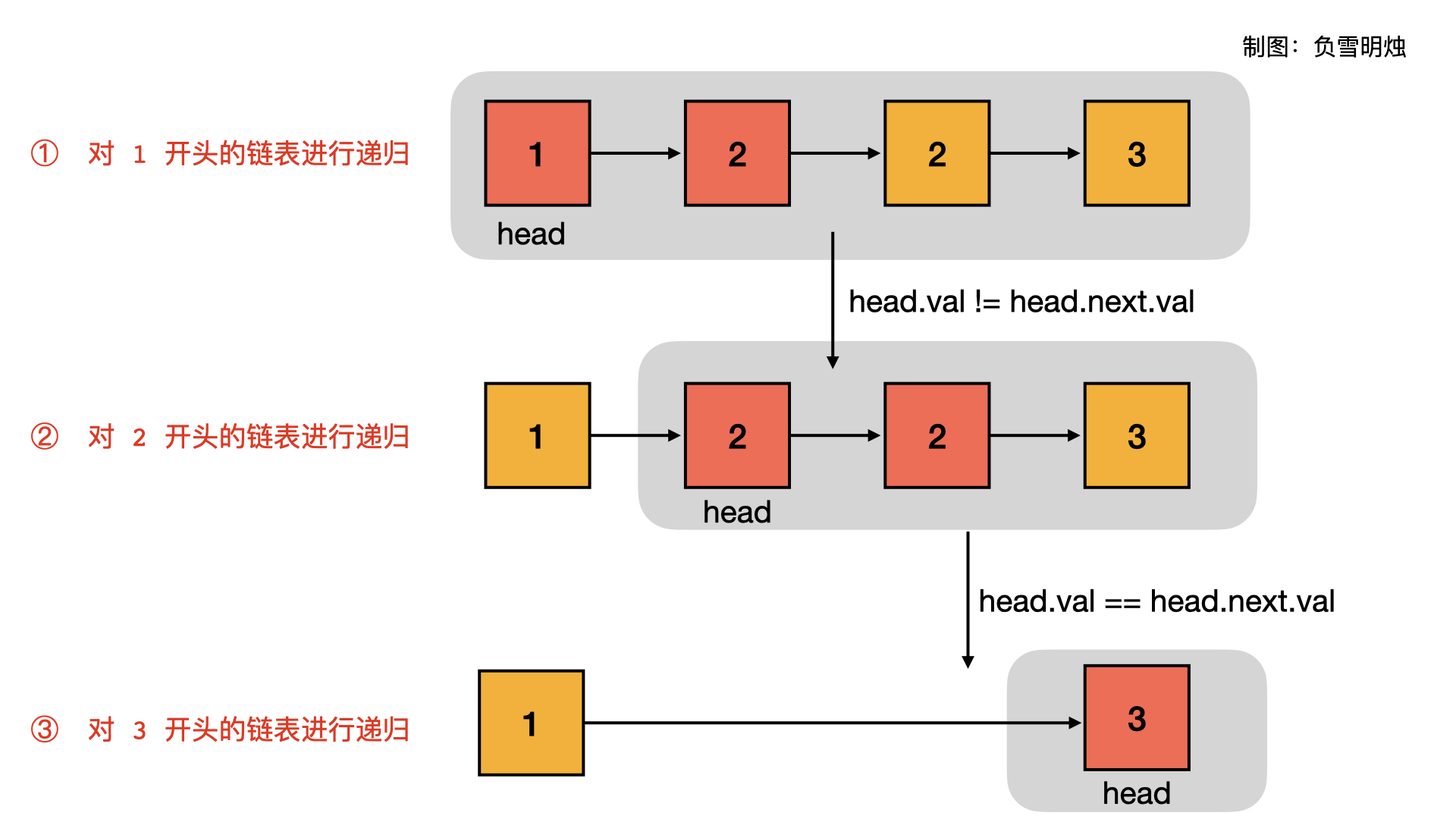
- 如果
head.val != head.next.val,说明头节点的值不等于下一个节点的值,所以当前的head节点必须保留;但是 head.next 节点要不要保留呢?我们还不知道,需要对head.next进行递归,即对head.next作为头节点的链表,去除值重复的节点。所以head.next = deleteDuplicates(head.next). - 如果
head.val == head.next.val,说明头节点的值等于下一个节点的值,所以当前的head节点必须删除;但是 head.next 节点要不要删除呢?我们还不知道,需要一直向后遍历寻找到与 head.val 不等的节点。与 head.val 相等的这一段链表都要删除,因此返回deleteDuplicates(move);
4. 返回结果
题目让我们返回删除了值重复的节点后剩余的链表,结合上面两种递归调用的情况。
- 如果
head.val != head.next.val,头结点需要保留,因此返回的是head; - 如果
head.val == head.next.val,头结点需要删除,需要返回的是deleteDuplicates(move);。
对链表 1 -> 2 -> 2 -> 3 递归的过程如下。
代码
1 | class Solution { |
前缀和
303. 区域和检索 - 数组不可变
给定一个整数数组 nums,求出数组从索引 i 到 j(i ≤ j)范围内元素的总和,包含 i、j 两点。
实现 NumArray 类:
- NumArray(int[] nums) 使用数组 nums 初始化对象
- int sumRange(int i, int j) 返回数组 nums 从索引 i 到 j(i ≤ j)范围内元素的总和,包含 i、j 两点(也就是 sum(nums[i], nums[i + 1], … , nums[j]))
示例:
1 | 输入: |
提示:
- 0 <= nums.length <= 10^4
- -10^5 <= nums[i] <= 10^5
- 0 <= i <= j < nums.length
- 最多调用 10^4 次 sumRange 方法
解题思路
preSum(前缀和)
今天这个题目让我们求一个区间 [i, j] 内的和,求区间和可以用 preSum 来做。
preSum 方法能快速计算指定区间段 i - j 的元素之和。它的计算方法是从左向右遍历数组,当遍历到数组的 i 位置时,preSum 表示 i 位置左边的元素之和。
假设数组长度为 N,我们定义一个长度为 N+1 的 preSum 数组,preSum[i] 表示该元素左边所有元素之和(不包含 i 元素)。然后遍历一次数组,累加区间 [0, i)范围内的元素,可以得到 preSum 数组。
求 preSum 的代码如下:
1 | N = len(nums) |
利用 preSum 数组,可以在 O(1) 的时间内快速求出 nums 任意区间 [i, j] (两端都包含) 的各元素之和。
sum(i, j) = preSum[j + 1] - preSum[i]
对于本题,可以在 NumArray 类的构造函数的里面,求数组每个位置的 preSum;当计算sumRange(i, j)的时候直接返回 preSum[j + 1] - preSum[i] 可以得到区间和。
下面以数组 [1, 12, -5, -6, 50, 3] 为例,展示了求 preSum 的过程。
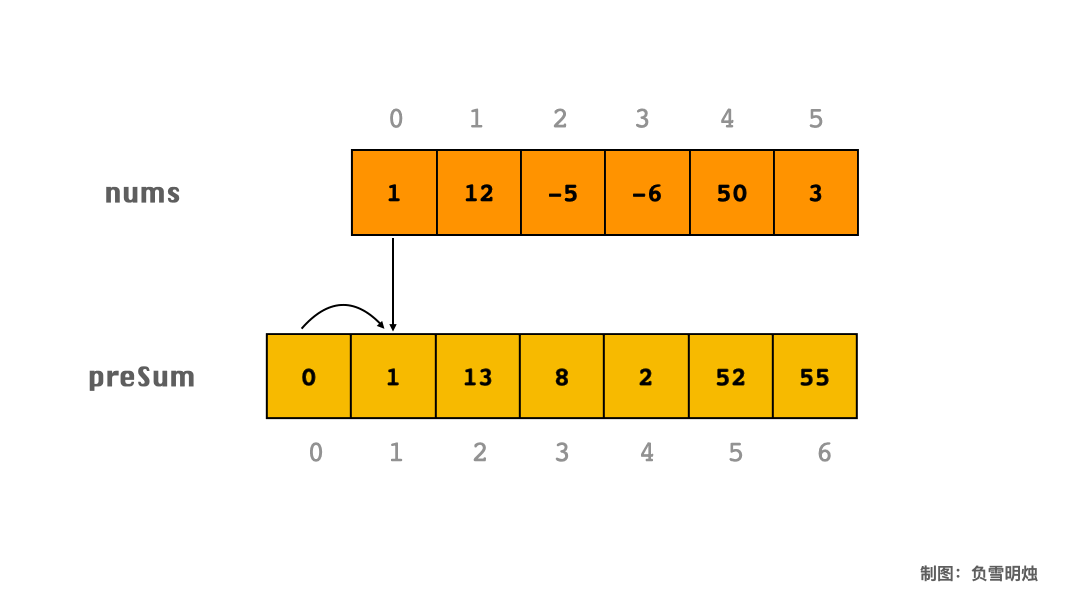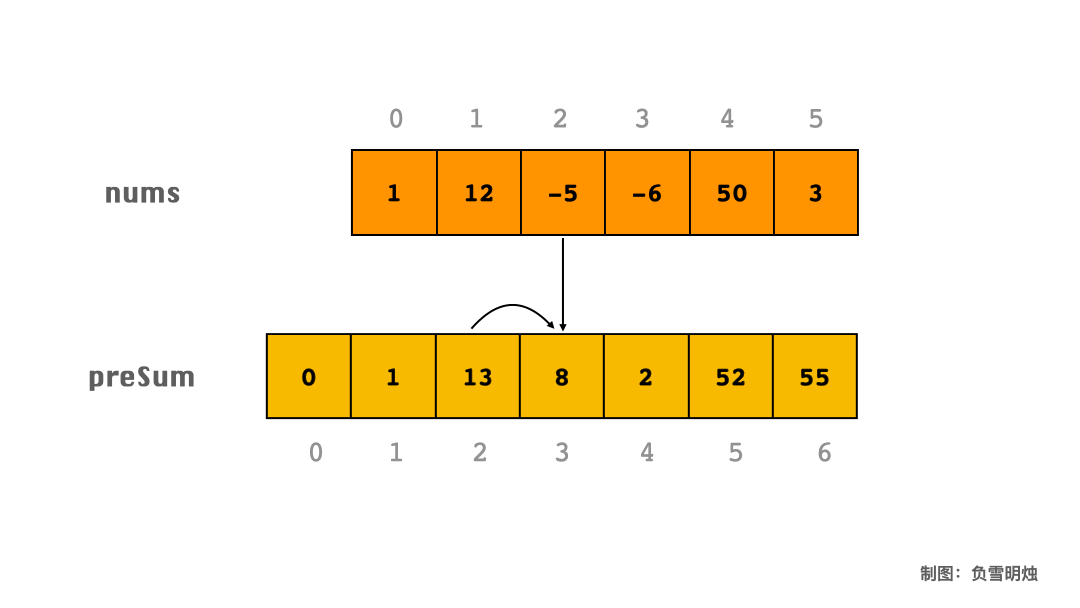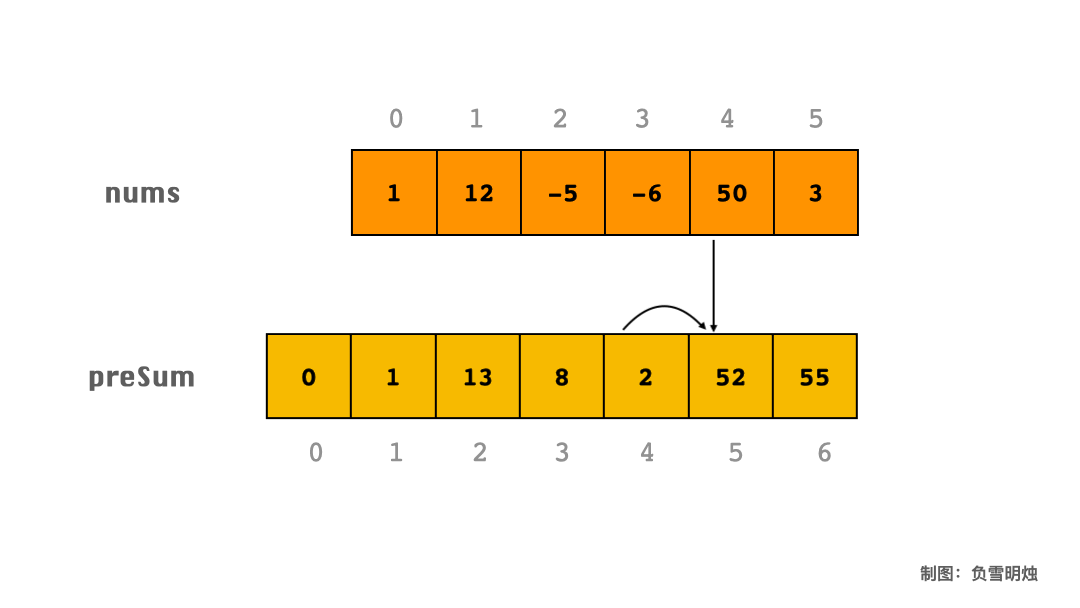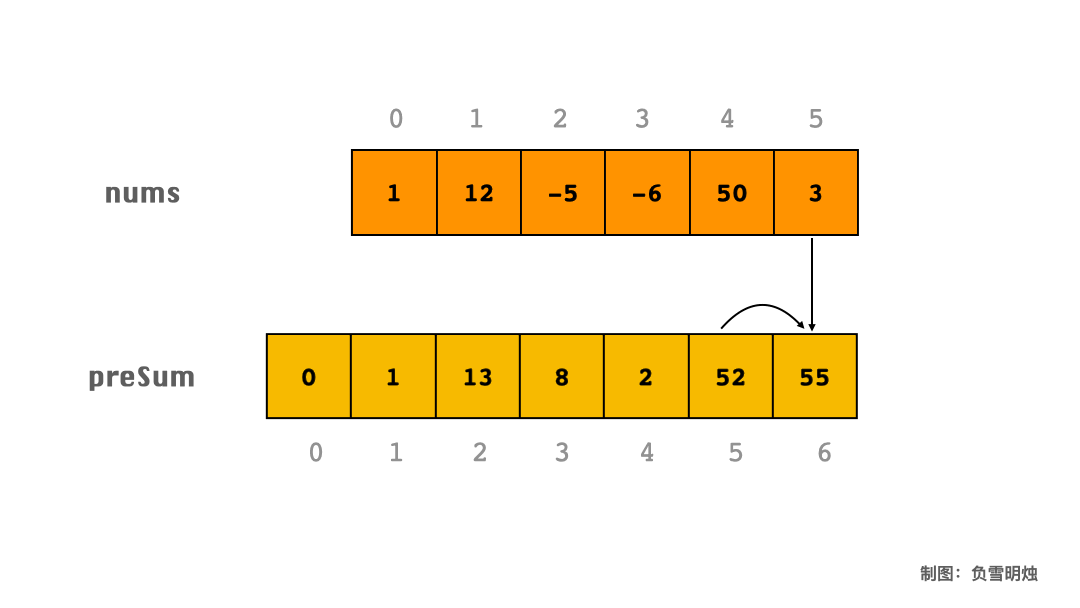
代码
1 | class NumArray { |
- 时间复杂度:构造函数的时间复杂度是 O(N), sumRange 函数调用的时间复杂度是 O(1)
- 空间复杂度:O(N)。
单调栈 Monotonic Stack
503. 下一个更大元素 II
给定一个循环数组(最后一个元素的下一个元素是数组的第一个元素),输出每个元素的下一个更大元素。数字 x 的下一个更大的元素是按数组遍历顺序,这个数字之后的第一个比它更大的数,这意味着你应该循环地搜索它的下一个更大的数。如果不存在,则输出 -1。
示例 1:
1 | 输入: [1,2,1] |
注意: 输入数组的长度不会超过 10000。
解题思路
今天题目的两个重点:
- 如何求下一个更大的元素
- 如何实现循环数组
1. 如何求下一个更大的元素
本题如果暴力求解,对于每个元素都向后去寻找比它更大的元素,那么时间复杂度 *O(N^2)*会超时。必须想办法优化。
我们注意到,暴力解法中,如果数组的前半部分是单调不增的,那么会有很大的计算资源的浪费。比如说 [6,5,4,3,8],对于前面的 [6,5,4,3] 等数字都需要向后遍历,当寻找到元素 8 时才找到了比自己大的元素;而如果已知元素 6 向后找到元素 8 才找到了比自己的大的数字,那么对于元素 [5,4,3] 来说,它们都比元素 6 更小,所以比它们更大的元素一定是元素 8,不需要单独遍历对 [5,4,3] 向后遍历一次!
根据上面的分析可知,可以遍历一次数组,如果元素是单调递减的(则他们的「下一个更大元素」相同),我们就把这些元素保存,直到找到一个较大的元素;把该较大元素逐一跟保存了的元素比较,如果该元素更大,那么它就是前面元素的「下一个更大元素」。
在实现上,我们可以使用「单调栈」来实现,单调栈是说栈里面的元素从栈底到栈顶是单调递增或者单调递减的(类似于汉诺塔)。
本题应该用个「单调递减栈」来实现。
建立「单调递减栈」,并对原数组遍历一次:
- 如果栈为空,则把当前元素放入栈内;
- 如果栈不为空,则需要判断当前元素和栈顶元素的大小:
- 如果当前元素比栈顶元素大:说明当前元素是前面一些元素的「下一个更大元素」,则逐个弹出栈顶元素,直到当前元素比栈顶元素小为止。
- 如果当前元素比栈顶元素小:说明当前元素的「下一个更大元素」与栈顶元素相同,则把当前元素入栈。
可以用下面的动图来帮助理解:
2. 如何实现循环数组
题目说给出的数组是循环数组,何为循环数组?就是说数组的最后一个元素下一个元素是数组的第一个元素,形状类似于「环」。
- 一种实现方式是,把数组复制一份到数组末尾,这样虽然不是严格的循环数组,但是对于本题已经足够了,因为本题对数组最多遍历两次。
- 另一个常见的实现方式是,使用取模运算 *%*可以把下标 i 映射到数组 nums 长度的 0 - N 内。
代码
栈里面需要保存元素在数组中的下标,而不是具体的数字。因为需要根据下标修改结果数组 res。
1 | class Solution { |
- 时间复杂度:*O(N)*,遍历了两次数组;
- 空间复杂度:*O(N)*,使用了额外空间「单调栈」,最坏情况下,栈内会保存数组的所有元素。
寻找下一个更大的元素需要移动的步数
给定一个数组,返回长度相同的数组。返回的数组的第i个位置的值应当是,对于原数组中的第i个元素,至少往右走多少步,才能遇到一个比自己大的元素(如果之后没有比自己大的元素,或者已经是最后一个元素,则在返回数组的对应位置放上-1)。
1 | 输入: [5,3,1,2,4] |
解题思路
我们维护这样一个单调递减的stack,stack内部存的是原数组的每个index。每当我们遇到一个比当前栈顶所对应的数(就是nums[stack.peek()])大的数的时候,我们就遇到了一个“大数“。这个”大数“比它之前多少个数大我们不知道,但是至少比当前栈顶所对应的数大。我们弹出栈内所有对应数比这个数小的栈内元素,并更新它们在返回数组中对应位置的值。因为这个栈本身的单调性,当我们栈顶元素所对应的数比这个元素大的时候,我们可以保证,栈内所有元素都比这个元素大。对于每一个元素,当它出栈的时候,说明它遇到了自己的next greater element,我们也就要更新return数组中的对应位置的值。如果一个元素一直不曾出栈,那么说明不存在next greater element,我们也就不用更新return数组了。
代码
1 | public static int[] nextExceed(int[] nums) { |

