
数组:为什么很多编程语言中数组都从0开始编号?
数组如何实现随机访问?
什么是数组?
数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
数组是如何实现根据下标随机访问数组元素的吗?
我们拿一个长度为 10 的 int 类型的数组 int[] a = new int[10]来举例。在我画的这个图中,计算机给数组 a[10],分配了一块连续内存空间 1000~1039,其中,内存块的首地址为 base_address = 1000。
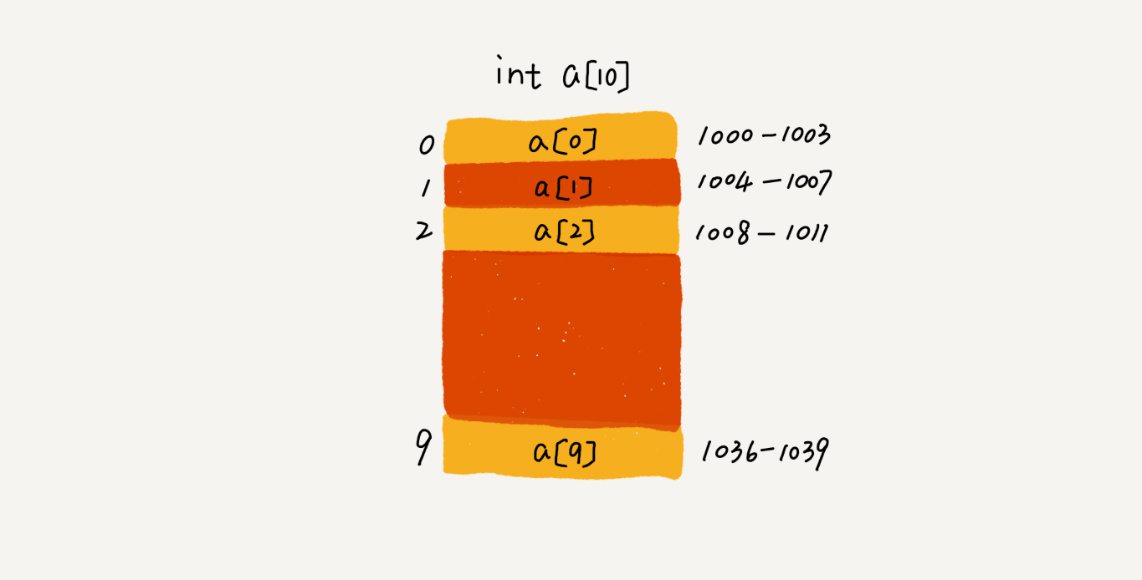
我们知道,计算机会给每个内存单元分配一个地址,计算机通过地址来访问内存中的数据。当计算机需要随机访问数组中的某个元素时,它会首先通过下面的寻址公式,计算出该元素存储的内存地址:
1 | a[i]_address = base_address + i * data_type_size |
其中 data_type_size 表示数组中每个元素的大小。我们举的这个例子里,数组中存储的是 int 类型数据,所以 data_type_size 就为 4 个字节。
容器和数组该如何选择?
- Java ArrayList 无法存储基本类型,比如 int、long,需要封装为 Integer、Long 类,而 Autoboxing、Unboxing 则有一定的性能消耗,所以如果特别关注性能,或者希望使用基本类型,就可以选用数组。
- 如果数据大小事先已知,并且对数据的操作非常简单,用不到 ArrayList 提供的大部分方法,也可以直接使用数组。
- 还有一个是我个人的喜好,当要表示多维数组时,用数组往往会更加直观。比如 Object[][] array;而用容器的话则需要这样定义:ArrayList<ArrayList<object>> array。
总结一下,对于业务开发,直接使用容器就足够了,省时省力。毕竟损耗一丢丢性能,完全不会影响到系统整体的性能。但如果你是做一些非常底层的开发,比如开发网络框架,性能的优化需要做到极致,这个时候数组就会优于容器,成为首选。
为什么数组要从 0 开始编号?
从数组存储的内存模型上来看,“下标”最确切的定义应该是“偏移(offset)”。前面也讲到,如果用 a 来表示数组的首地址,a[0]就是偏移为 0 的位置,也就是首地址,a[k]就表示偏移 k 个 type_size 的位置,所以计算 a[k]的内存地址只需要用这个公式:
1 | a[k]_address = base_address + k * type_size |
但是,如果数组从 1 开始计数,那我们计算数组元素 a[k]的内存地址就会变为:
1 | a[k]_address = base_address + (k-1) * type_size |
对比两个公式,我们不难发现,从 1 开始编号,每次随机访问数组元素都多了一次减法运算,对于 CPU 来说,就是多了一次减法指令。
数组作为非常基础的数据结构,通过下标随机访问数组元素又是其非常基础的编程操作,效率的优化就要尽可能做到极致。所以为了减少一次减法操作,数组选择了从 0 开始编号,而不是从 1 开始。
不过我认为,上面解释得再多其实都算不上压倒性的证明,说数组起始编号非 0 开始不可。所以我觉得最主要的原因可能是历史原因。
C 语言设计者用 0 开始计数数组下标,之后的 Java、JavaScript 等高级语言都效仿了 C 语言,或者说,为了在一定程度上减少 C 语言程序员学习 Java 的学习成本,因此继续沿用了从 0 开始计数的习惯。实际上,很多语言中数组也并不是从 0 开始计数的,比如 Matlab。甚至还有一些语言支持负数下标,比如 Python。
课后思考
1.前面我基于数组的原理引出 JVM 的标记清除垃圾回收算法的核心理念。我不知道你是否使用 Java 语言,理解 JVM,如果你熟悉,可以在评论区回顾下你理解的标记清除垃圾回收算法。
分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后,统一回收掉所有被标记的对象,也可以反过来,标记存活的对象,统一回收所有未被标记的对象。
大多数主流虚拟机采用可达性分析算法来判断对象是否存活,在标记阶段,会遍历所有 GC ROOTS,将所有 GC ROOTS 可达的对象标记为存活。
缺点主要有两个:1. 执行效率不稳定,如果Java堆中包含大量对象,而且其中大部分是需要被回收的,这时必须进行大量标记和清除的动作,导致标记和清除两个过程的执行效率都随对象数量增长而降低;2. 内存碎片化问题,标记、清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致当以后在程序运行过程中需要分配较大对象时无法找到足够的连续内存而不得不提前触发一次垃圾回收动作。
2.前面我们讲到一维数组的内存寻址公式,那你可以思考一下,类比一下,二维数组的内存寻址公式是怎样的呢?
二维数组内存寻址:
对于 m * n 的数组,a [i][j] (i < m, j < n)的地址为:
address = base_address + ( i * n + j) * type_size

