
10 | 递归:如何用三行代码找到“最终推荐人”?
递归需要满足的三个条件
1. 一个问题的解可以分解为几个子问题的解
何为子问题?子问题就是数据规模更小的问题。比如,前面讲的电影院的例子,你要知道,“自己在哪一排”的问题,可以分解为“前一排的人在哪一排”这样一个子问题。
2. 这个问题与分解之后的子问题,除了数据规模不同,求解思路完全一样
比如电影院那个例子,你求解“自己在哪一排”的思路,和前面一排人求解“自己在哪一排”的思路,是一模一样的。
3. 存在递归终止条件
把问题分解为子问题,把子问题再分解为子子问题,一层一层分解下去,不能存在无限循环,这就需要有终止条件。还是电影院的例子,第一排的人不需要再继续询问任何人,就知道自己在哪一排,也就是 f(1)=1,这就是递归的终止条件。
如何编写递归代码?
写递归代码最关键的是写出递推公式,找到终止条件,剩下将递推公式转化为代码就很简单了。
你先记住这个理论。我举一个例子,带你一步一步实现一个递归代码,帮你理解。
假如这里有 n 个台阶,每次你可以跨 1 个台阶或者 2 个台阶,请问走这 n 个台阶有多少种走法?如果有 7 个台阶,你可以 2,2,2,1 这样子上去,也可以 1,2,1,1,2 这样子上去,总之走法有很多,那如何用编程求得总共有多少种走法呢?
我们仔细想下,实际上,可以根据第一步的走法把所有走法分为两类,第一类是第一步走了 1 个台阶,另一类是第一步走了 2 个台阶。所以 n 个台阶的走法就等于先走 1 阶后,n-1 个台阶的走法 加上先走 2 阶后,n-2 个台阶的走法。用公式表示就是:
1 | f(n) = f(n-1)+f(n-2) |
这里其实就是斐波那契数列,或者你自己在本子上画一下就知道了,第一阶有1种走法,第二阶有2种走法,第三阶有3种走法,第四阶有5种走法,第五阶有8种走法,这个走法的规律正好符合斐波那契数列1(这个1在此例子省略了)、1、2、3、5、8、13、21….不管哪个数都是前两个数的和,那么想象每个数下面都有一个类似数组一样的下标,那么第n个数就等于第n-1位置的数加上第n-2位置的数也就是F(n) = F(n-1) + F(n-2)
有了递推公式,递归代码基本上就完成了一半。我们再来看下终止条件。当有一个台阶时,我们不需要再继续递归,就只有一种走法。所以 f(1)=1。这个递归终止条件足够吗?我们可以用 n=2,n=3 这样比较小的数试验一下。
n=2 时,f(2)=f(1)+f(0)。如果递归终止条件只有一个 f(1)=1,那 f(2) 就无法求解了。所以除了 f(1)=1 这一个递归终止条件外,还要有 f(0)=1,表示走 0 个台阶有一种走法,不过这样子看起来就不符合正常的逻辑思维了。所以,我们可以把 f(2)=2 作为一种终止条件,表示走 2 个台阶,有两种走法,一步走完或者分两步来走。
所以,递归终止条件就是 f(1)=1,f(2)=2。这个时候,你可以再拿 n=3,n=4 来验证一下,这个终止条件是否足够并且正确。
我们把递归终止条件和刚刚得到的递推公式放到一起就是这样的:
1 | f(1) = 1; |
有了这个公式,我们转化成递归代码就简单多了。最终的递归代码是这样的:
1 | int f(int n) { |
我总结一下,写递归代码的关键就是找到如何将大问题分解为小问题的规律,并且基于此写出递推公式,然后再推敲终止条件,最后将递推公式和终止条件翻译成代码。
虽然我讲了这么多方法,但是作为初学者的你,现在是不是还是有种想不太清楚的感觉呢?实际上,我刚学递归的时候,也有这种感觉,这也是文章开头我说递归代码比较难理解的地方。
刚讲的电影院的例子,我们的递归调用只有一个分支,也就是说“一个问题只需要分解为一个子问题”,我们很容易能够想清楚“递”和“归”的每一个步骤,所以写起来、理解起来都不难。
但是,当我们面对的是一个问题要分解为多个子问题的情况,递归代码就没那么好理解了。
像我刚刚讲的第二个例子,人脑几乎没办法把整个“递”和“归”的过程一步一步都想清楚。
计算机擅长做重复的事情,所以递归正合它的胃口。而我们人脑更喜欢平铺直叙的思维方式。当我们看到递归时,我们总想把递归平铺展开,脑子里就会循环,一层一层往下调,然后再一层一层返回,试图想搞清楚计算机每一步都是怎么执行的,这样就很容易被绕进去。
对于递归代码,这种试图想清楚整个递和归过程的做法,实际上是进入了一个思维误区。很多时候,我们理解起来比较吃力,主要原因就是自己给自己制造了这种理解障碍。那正确的思维方式应该是怎样的呢?
如果一个问题 A 可以分解为若干子问题 B、C、D,你可以假设子问题 B、C、D 已经解决,在此基础上思考如何解决问题 A。而且,你只需要思考问题 A 与子问题 B、C、D 两层之间的关系即可,不需要一层一层往下思考子问题与子子问题,子子问题与子子子问题之间的关系。屏蔽掉递归细节,这样子理解起来就简单多了。
因此,编写递归代码的关键是,只要遇到递归,我们就把它抽象成一个递推公式,不用想一层层的调用关系,不要试图用人脑去分解递归的每个步骤。
递归代码要警惕重复计算
除此之外,使用递归时还会出现重复计算的问题。刚才我讲的第二个递归代码的例子,如果我们把整个递归过程分解一下的话,那就是这样的:
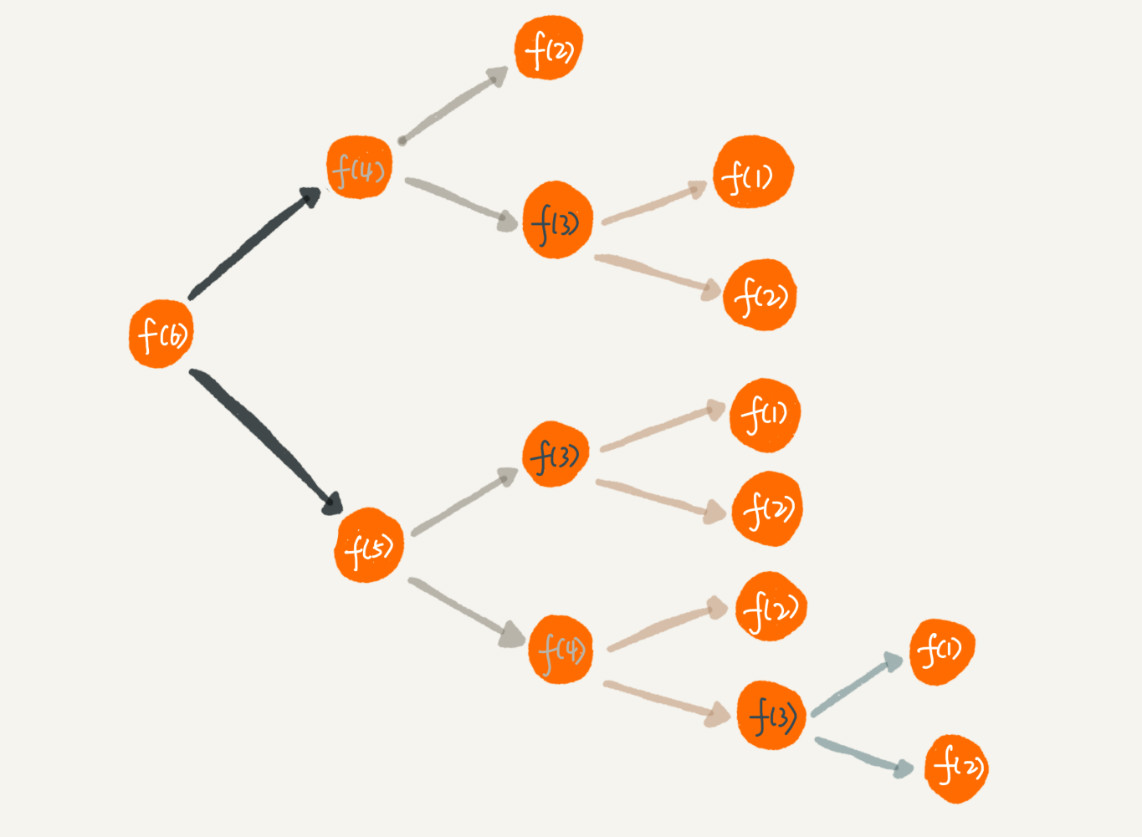
从图中,我们可以直观地看到,想要计算 f(5),需要先计算 f(4) 和 f(3),而计算 f(4) 还需要计算 f(3),因此,f(3) 就被计算了很多次,这就是重复计算问题。
为了避免重复计算,我们可以通过一个数据结构(比如散列表)来保存已经求解过的 f(k)。当递归调用到 f(k) 时,先看下是否已经求解过了。如果是,则直接从散列表中取值返回,不需要重复计算,这样就能避免刚讲的问题了。
按照上面的思路,我们来改造一下刚才的代码:
1 | public int f(int n) { |
除了堆栈溢出、重复计算这两个常见的问题。递归代码还有很多别的问题。在时间效率上,递归代码里多了很多函数调用,当这些函数调用的数量较大时,就会积聚成一个可观的时间成本。在空间复杂度上,因为递归调用一次就会在内存栈中保存一次现场数据,所以在分析递归代码空间复杂度时,需要额外考虑这部分的开销,比如我们前面讲到的电影院递归代码,空间复杂度并不是 O(1),而是 O(n)。
课后思考
我们平时调试代码喜欢使用 IDE 的单步跟踪功能,像规模比较大、递归层次很深的递归代码,几乎无法使用这种调试方式。对于递归代码,你有什么好的调试方法呢?
调试递归:
1.打印日志发现,递归值。
2.结合条件断点进行调试。

