
涂鸦智能
- redis为什么这么快
- redis为什么是单线程
- 3000万数据的表,如何进行优化
- 分库分表、多维度查询
滴滴
堆外内存
类加载机制
双亲委派机制,如何打破
不同的类加载器加载的类是不是同一个类
https://cloud.tencent.com/developer/news/627029
不同类加载器加载的类在 JVM 看来是两个不同的类,因为在 JVM 中一个类的唯一标识是类加载器+类名。通过这种方式我们就能够同时加载 C 的两个不同版本的类,即使它类名是一样的。注意,这里类加载器指的是类加载器的实例,并不是一定要定义两个不同类加载器
线程池原理以及使用场景
synchronized和ReentrantLock的区别(是否是重入锁)
ReentrantLock非公平锁和公平锁如何做到的
synchronized锁升级原理
redis分布式锁如何使用
业务没执行完,分布式锁过期释放,如何解决
springcloud和dubbo的区别
rpc协议和http协议的区别
https的原理
序列化方式有哪几种,dubbo默认是哪种
mysql查询优化
mysql为什么用b+树
快手
- 23. 合并K个升序链表
- HashMap在jdk1.7扩容过程
- HashMap什么情况下会链表成环
- HashMap为什么线程不安全
- 反射原理以及使用场景
- 创建对象的几种形式
- 聚合根、实体在业务中的应用
- redis集群、高可用、持久化
- 本地事务表如果TPS太高,如何优化
酷家乐
- 最长回文子串
- 带
+ - * /()的基本计算器 - binlog存储形式(row和statement)
- mvcc具体是如何解决幻读的?
- 类加载过程
哈罗单车
两个不同版本的类,如果我都想去加载?如何去做(自定义两个类加载器去加载)
MySQL为什么不用平衡树?
因为数据是存储在磁盘上的,进行查询操作的时,需要先将数据加载到内存中(磁盘IO操作)。而数据并不能一次性全部加载到内存中,只能逐一加载每个磁盘页(对应树的一个节点),并且磁盘IO操作很慢,平衡二叉树由于深度过大而造成磁盘IO读写过于频繁,进而导致效率低下。为了减少磁盘的IO次数,就需要降低树的深度,那么就引出了B树和B+树:每个节点存储多个元素,采用多叉树结构。所以使用B+树而不是平衡二叉树。
B树的每个节点可以存储多个关键字,它将节点大小设置为磁盘页的大小,充分利用了磁盘预读的功能。每次读取磁盘页时就会读取一整个节点。也正因每个节点存储着非常多个关键字,树的深度就会非常的小。进而要执行的磁盘读取操作次数就会非常少,更多的是在内存中对读取进来的数据进行查找。
总结:平衡树没能充分利用磁盘预读(局部性原理)功能,而B+树每个节点是一个磁盘页,每个节点包含多个key,每次加载能把一页数据全部加载到内存,提高了缓存命中率。
MySQL为什么使用B+树索引而不是B树索引?
- B+树叶子节点使用双向链表连接,范围查询非常方便;而B树必须用中序遍历的方法按序扫库,效率低下
- B+树非叶子节点不保存数据,同样的磁盘页大小容纳的关键字更多,一次性读入内存的关键字也就越多,相对来说说IO次数就降低了
- B+树查询效率更稳定:因为B+树非叶子节点不保存数据,所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
网易
cms和G1垃圾回收器的区别?为什么G1适合大内存,G1如何做到可预测的低停顿的?
G1收集器之所以能建立可预测的停顿时间模型,是因为它将Region作为单次回收的最小单元,即每次收集到的内存空间都是Region大小的整数倍,这样可以有计划地避免在整个Java堆中进行全区域的垃圾收集。更具体的处理思路是让G1收集器去跟踪各个Region里面的垃圾堆积的“价值”大小,价值即回收所获得的空间大小以及回收所需时间的经验值,然后在后台维护一个优先级列表,每次根据用户设定允许的收集停顿时间(使用参数 - XX:MaxGCPauseMills指定,默认值是200毫秒),优先处理回收价值收益最大的那些Region,这也就是“Garbage First”名称的由来。这种使用Region划分内存空间,以及具有优先级的区域回收方式,保证了G1收集器在有限的时间内获取尽可能高的收集效率。
读写锁的实现细节
volatile保证了什么?如何保证的?内存屏障的指令有哪些?
SQL注入是啥,以及它的原理,如何避免?
MySQL如何解决幻读?(除了MVCC之外还能如何解决?)
kafka消息投递语义精准一次性(Exactly-once)是如何保证的?
这个特性是怎么实现的呢?在底层,它和TCP的工作原理有点像,每一批发送到Kafka的消息都将包含一个序列号,broker将使用这个序列号来删除重复的发送。和只能在瞬态内存中的连接中保证不重复的TCP不同,这个序列号被持久化到副本日志,所以,即使分区的leader挂了,其他的broker接管了leader,新leader仍可以判断重新发送的是否重复了。这种机制的开销非常低:每批消息只有几个额外的字段:
- PID,在Producer初始化时分配,作为每个Producer会话的唯一标识;
- 序列号(sequence number),Producer发送的每条消息(更准确地说是每一个消息批次,即ProducerBatch)都会带有此序列号,从0开始单调递增。Broker根据它来判断写入的消息是否可接受。
美团
- 148. 排序链表
- JVM内存区域
- CMS垃圾回收器
- 垃圾回收算法
- 类加载过程
- 线程池原理,使用场景,参数如何配置,如何预创建线程
- Spring AOP原理
- redis使用场景
- redis单线程为什么这么快
- redis为什么能支撑10万QPS
阿里
布隆过滤器如何降低误判率
增加hash函数个数或者增大位数组容量
jdk8为什么要取消方法区,设立元空间
元空间参数如何配置
-XX:MetaspaceSize:Metaspace 空间初始大小,如果不设置的话,默认是20.79M,这个初始大小是触发首次 Metaspace Full GC 的阈值,例如 -XX:MetaspaceSize=256M
-XX:MaxMetaspaceSize:Metaspace 最大值,默认不限制大小,但是线上环境建议设置,例如
-XX:MaxMetaspaceSize=256M
-XX:MinMetaspaceFreeRatio:最小空闲比,当 Metaspace 发生 GC 后,会计算 Metaspace 的空闲比,如果空闲比(空闲空间/当前 Metaspace 大小)小于此值,就会触发 Metaspace 扩容。默认值是 40 ,也就是 40%,例如 -XX:MinMetaspaceFreeRatio=40
-XX:MaxMetaspaceFreeRatio:最大空闲比,当 Metaspace 发生 GC 后,会计算 Metaspace 的空闲比,如果空闲比(空闲空间/当前 Metaspace 大小)大于此值,就会触发 Metaspace 释放空间。默认值是 70 ,也就是 70%,例如 -XX:MaxMetaspaceFreeRatio=70
- 建议将 MetaspaceSize 和 MaxMetaspaceSize 设置为同样大小,避免频繁扩容。
如何减少回表
oom如何排查
https://www.cnblogs.com/lujiango/p/9650927.html
1.确认是不是内存本身就分配过小
jmap -heap pid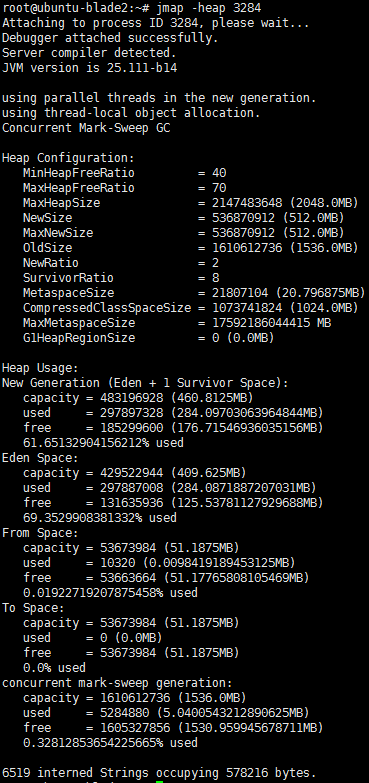
如图,可以查看新生代,老年代堆内存的分配大小以及使用情况,看是否本身分配过小。
2.找到最耗内存的对象
jmap -histo:live pid | more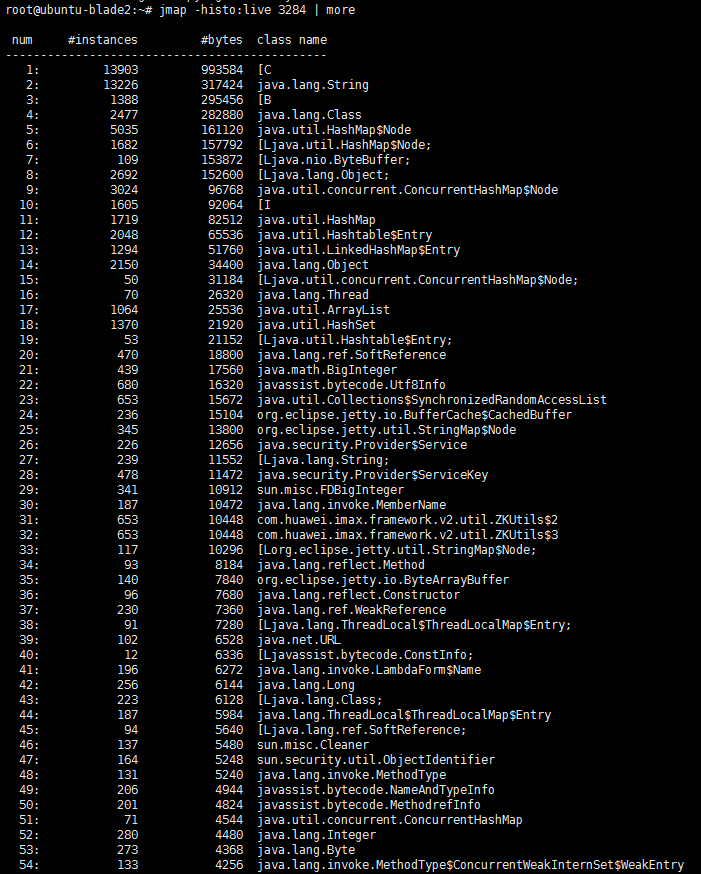
如图,结果以表格的形式显示存活对象的信息,并按照所占内存大小排序:
实例数,所占内存大小,类名
如果发现某类对象占用内存很大,很可能是类对象创建太多,且一直未释放。例如:
(1)申请完资源后,未调用close释放资源
(2)消费者消费速度慢,生产者不断往队列中投递任务,导致队列中任务累积过多
3.确认释放是资源耗尽
pstree:查看进程创建的线程数
netstat:网络连接数
还有另一种方法,通过
ll /proc/pid/fd 查看占用句柄
ll /proc/pid/task 查看线程数
例如,某一台显示服务器的sshd进程是1041,查看:
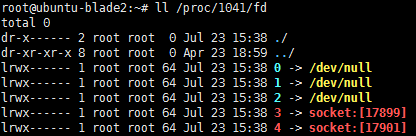
sshd共占用了5个句柄。
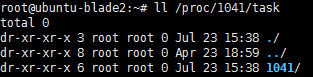
sshd只有一个主线程为1041,并没有多线程。
阿里(商家)
- 本地缓存一般适用于什么场景?如何保证缓存一致性

