kafka入门
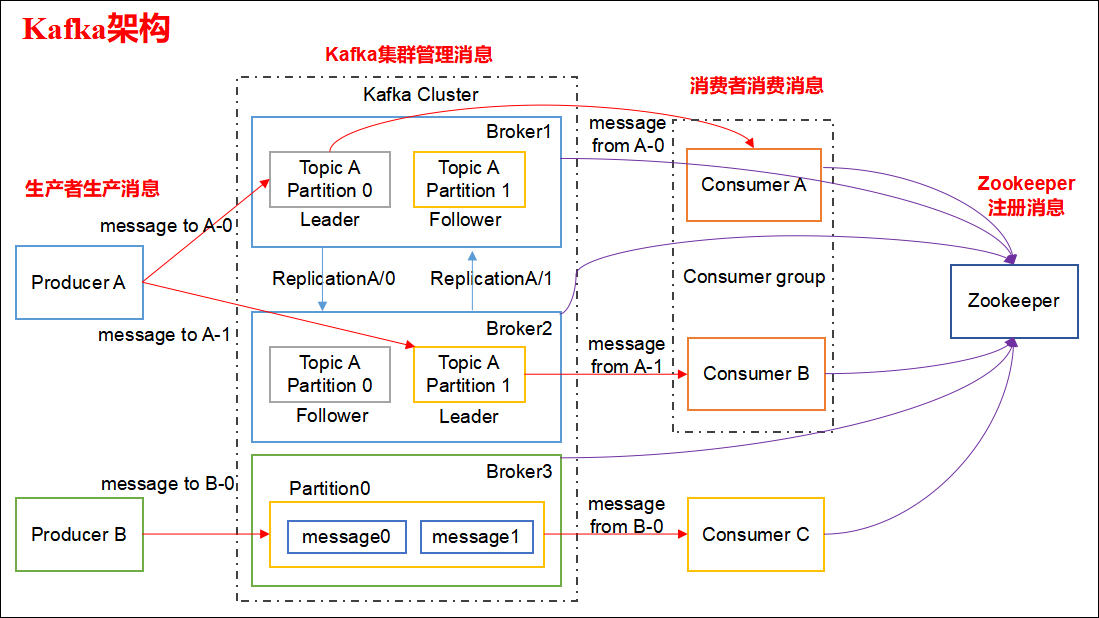
整体架构图
topic
topic可以简单认为是一个队列,每个队列做不同的事情,队列之间相对隔离;每个队列都有不同的名字,这样我们就知道往哪个队列丢数据,也知道从哪个队列拿数据了。我们可以有多个生产者**往同一个队列(topic)丢数据,多个消费者从同一个队列(topic)**拿数据
partition
为了提高每个队列(topic)的吞吐量,kafka会把topic进行分区(Partition)。每个topic包含多个分区。
所以,生产者实际上是往一个topic名为sonder中的分区(Partition)丢数据,消费者实际上是从一个topic名为sonder的分区(Partition)取数据
broker
一台Kafka服务器叫做Broker,Kafka集群就是多台Kafka服务器:
一个topic会分为多个partition,实际上partition会分布在不同的broker中,举个例子:
生产者往一个topic里面丢数据,实际上数据会在partition中,partition会分布在不同的broker(服务器)上。
由此得知:Kafka是天然分布式的。
消费者和消费者组
既然数据是保存在partition中的,那么消费者实际上也是从partition中取数据。
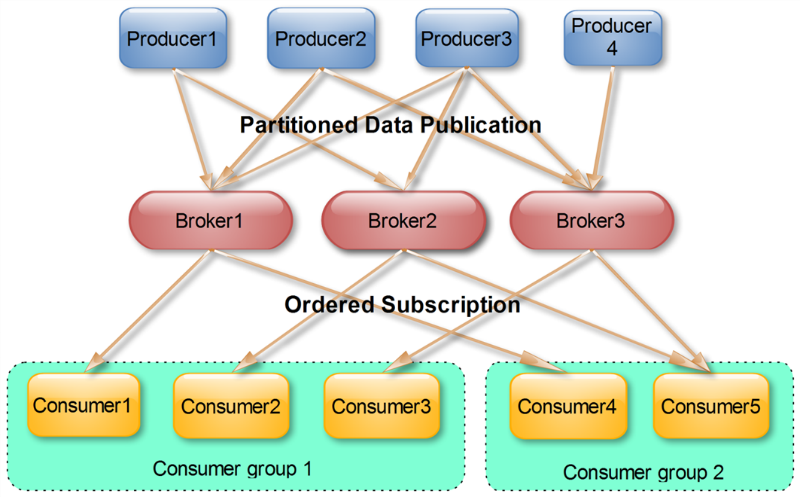
使用 Consumer high level API 时,同一 Topic 的一条消息只能被同一个 Consumer Group 内的一个 Consumer 消费,但多个 Consumer Group 可同时消费这一消息。
这是 Kafka 用来实现一个 Topic 消息的广播(发给所有的 Consumer)和单播(发给某一个 Consumer)的手段。一个 Topic 可以对应多个 Consumer Group。如果需要实现广播,只要每个 Consumer 有一个独立的 Group 就可以了。要实现单播只要所有的 Consumer 在同一个 Group 里。用 Consumer Group 还可以将 Consumer 进行自由的分组而不需要多次发送消息到不同的 Topic。
多个消费者组成一个消费者组,每个消费者组之间相互独立。同一个消费者组中的不同消费者不能同时消费同一个分区的数据。但不同的消费者组可以消费相同的分区的数据(广播消费)。
每个消费者组唯一对应一个topic,一个topic下面可能有多个消费者组,这样就实现了广播消费。
注意:如果消费者不指定消费者组,那么将会使用默认的消费者组,每个topic都有一个默认消费者组。
关于消费者数量,要注意几点:
- 如果消费者组中的某个消费者挂了,那么其中一个消费者可能就要消费两个partition了
- 如果只有三个partition,而消费者组有4个消费者,那么一个消费者会空闲(一个分区不会被两个消费者同时消费)
- 如果多加入一个消费者组,无论是新增的消费者组还是原本的消费者组,都能消费topic的全部数据。(消费者组之间从逻辑上它们是独立的)
高可用
Kafka分区如果出现故障怎么办?
现在我们已经知道了往topic里边丢数据,实际上这些数据会分到不同的partition上,这些partition存在不同的broker上。分布式肯定会带来问题:“万一其中一台broker(Kafka服务器)出现网络抖动或者挂了,怎么办?”
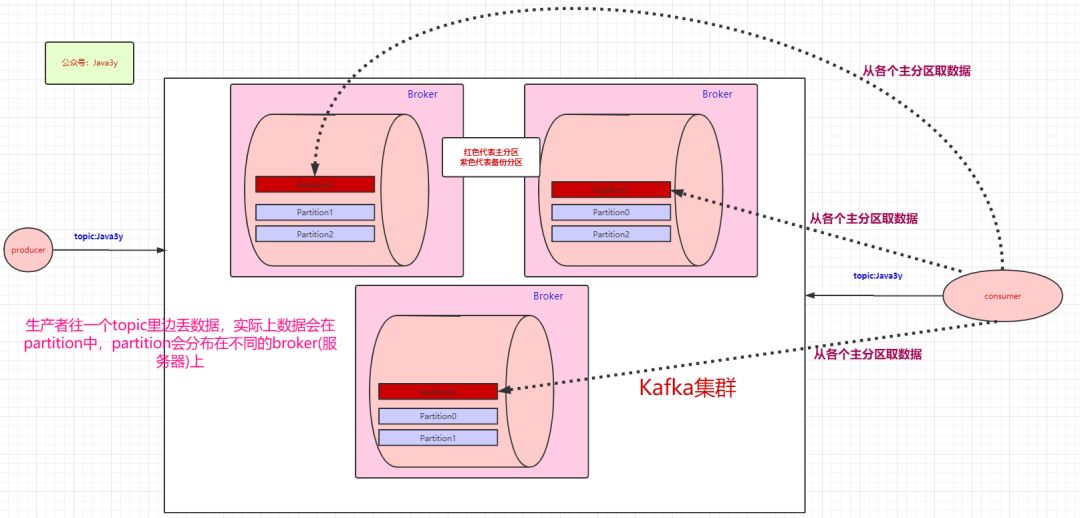
Kafka是这样做的:我们数据存在不同的partition上,那kafka就把这些partition做备份(replica)。比如,现在我们有三个partition,分别存在三台broker上。每个partition都会备份,这些备份散落在不同的broker上。
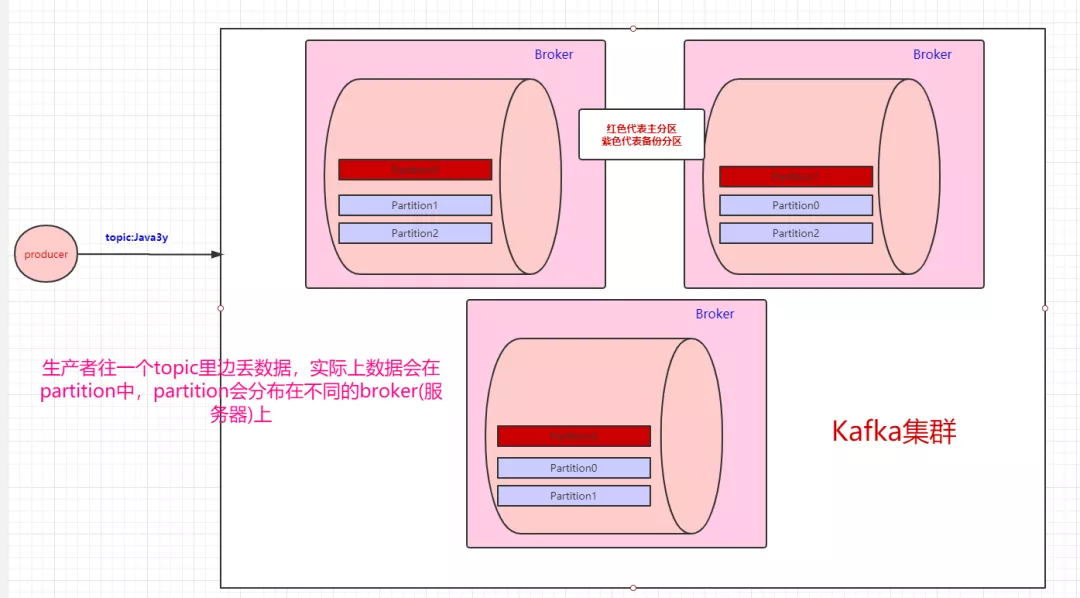
红色块的partition代表的是主分区,紫色的partition块代表的是备份分区。生产者往topic丢数据,是与主分区交互,消费者消费topic的数据,也是与主分区交互。
备份分区仅仅用作于备份,不做读写。如果某个Broker挂了,那就会选举出其他Broker的partition来作为主分区,这就实现了高可用。
ISR(in-sync-replica)机制
可靠性
Kafka消息可靠性是如何保证的?
Acks机制:
- 0:不进行消息接收是否成功的确认(默认值),会丢失数据。
- 1:当Leader副本接收成功后,返回接收成功确认信息,主备切换可能会丢失数据。
- -1(all):当Leader和Follower副本都接收成功后,返回接收成功的确认信息。
消息投递语义
https://www.cnblogs.com/luxiaoxun/p/13048474.html
消息投递语义有三种:
At most once:最多一次,消息可能丢失,但不会重复
At least once:最少一次,消息不会丢失,可能会重复
Exactly once:有且只有一次,消息不会丢失或重复,只会消费一次(0.11版本实现,仅限于下游也是kafka)
幂等:partition内部的exactly-once顺序语义
幂等操作,是指可以执行多次,而不会产生与仅执行一次不同结果的操作,Producer的send操作现在是幂等的。在任何导致producer重试的情况下,相同的消息,如果被producer发送多次,也只会被写入Kafka一次。要打开此功能,并让所有partition获得exactly-once delivery、无数据丢失和in-order语义,需要修改broker的配置:enable.idempotence = true。
这个功能如何工作?它的工作方式类似于TCP:发送到Kafka的每批消息将包含一个序列号,该序列号用于重复数据的删除。与TCP不同,TCP只能在transient in-memory中提供保证。序列号将被持久化存储topic中,因此即使leader replica失败,接管的任何其他broker也将能感知到消息是否重复。
这种机制的开销相当低:它只是在每批消息中添加了几个额外字段:
- PID,在Producer初始化时分配,作为每个Producer会话的唯一标识;
- 序列号(sequence number),Producer发送的每条消息(更准确地说是每一个消息批次,即ProducerBatch)都会带有此序列号,从0开始单调递增。Broker根据它来判断写入的消息是否可接受。
事务机制:跨partition的原子性写操作
https://www.cnblogs.com/luxiaoxun/p/13048474.html
高性能
为什么用kafka不用本地队列
高吞吐
消息持久化
分布式易拓展
kafka为什么这么快
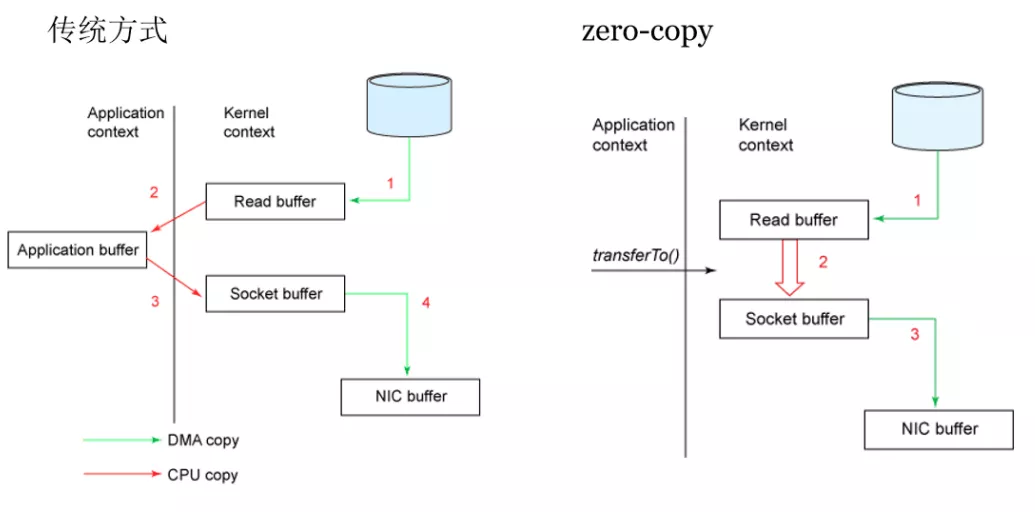
Kafka速度的秘诀在于,它把所有的消息都变成一个批量的文件,并且进行合理的批量压缩,减少网络IO损耗,通过mmap提高I/O速度,写入数据的时候由于单个Partion是末尾添加所以速度最优;读取数据的时候配合sendfile直接暴力输出。
具体分写入和读取两个方面:
写入:
- 使用顺序写入
- Memory Mapped Files
读取:
- 基于sendfile实现Zero Copy
- 批量压缩
什么是零拷贝?