Elfred
上善若水

29讲
29 | 堆的应用:如何快速获取到Top 10最热门的搜索关键词?
堆的应用一:优先级队列
1. 合并有序小文件
假设我们有 100 个小文件,每个文件的大小是 100MB,每个文件中存储的都是有序的字符串。我们希望将这些 100 个小文件合并成一个有序的大文件。这里就会用到优先级队列。
整体思路有点像归并排序中的合并函数。我们从这 100 个文件中,各取第一个字符串,放入数组中,然后比较大小,把最小的那个字符串放入合并后的大文件中,并从数组中删除。
假设,这个最小的字符串来自于 13.txt 这个小文件,我们就再从这个小文件取下一个字符串,放到数组中,重新比较大小,并且选择最小的放入合并后的大文件,将它从数组中删除。依次类推,直到所有的文件中的数据都放入到大文件为止。
这里我们用数组这种数据结构,来存储从小文件中取出来的字符串。每次从数组中取最小字符串,都需要循环遍历整个数组,显然,这不是很高效。有没有更加高效方法呢?
这里就可以用到优先级队列,也可以说是堆。我们将从小文件中取出来的字符串放入到小顶堆中,那堆顶的元素,也就是优先级队列队首的元素,就是最小的字符串。我们将这个字符串放入到大文件中,并将其从堆中删除。然后再从小文件中取出下一个字符串,放入到堆中。循环这个过程,就可以将 100 个小文件中的数据依次放入到大文件中。
我们知道,删除堆顶数据和往堆中插入数据的时间复杂度都是 O(logn),n 表示堆中的数据个数,这里就是 100。是不是比原来数组存储的方式高效了很多呢?
28讲
28 | 堆和堆排序:为什么说堆排序没有快速排序快?
如何理解“堆”?
前面我们提到,堆是一种特殊的树。我们现在就来看看,什么样的树才是堆。我罗列了两点要求,只要满足这两点,它就是一个堆。
- 堆是一个完全二叉树;
- 堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值。
我分别解释一下这两点。
第一点,堆必须是一个完全二叉树。还记得我们之前讲的完全二叉树的定义吗?完全二叉树要求,除了最后一层,其他层的节点个数都是满的,最后一层的节点都靠左排列。
第二点,堆中的每个节点的值必须大于等于(或者小于等于)其子树中每个节点的值。实际上,我们还可以换一种说法,堆中每个节点的值都大于等于(或者小于等于)其左右子节点的值。这两种表述是等价的。
对于每个节点的值都大于等于子树中每个节点值的堆,我们叫做“大顶堆”。对于每个节点的值都小于等于子树中每个节点值的堆,我们叫做“小顶堆”。
定义解释清楚了,你来看看,下面这几个二叉树是不是堆?
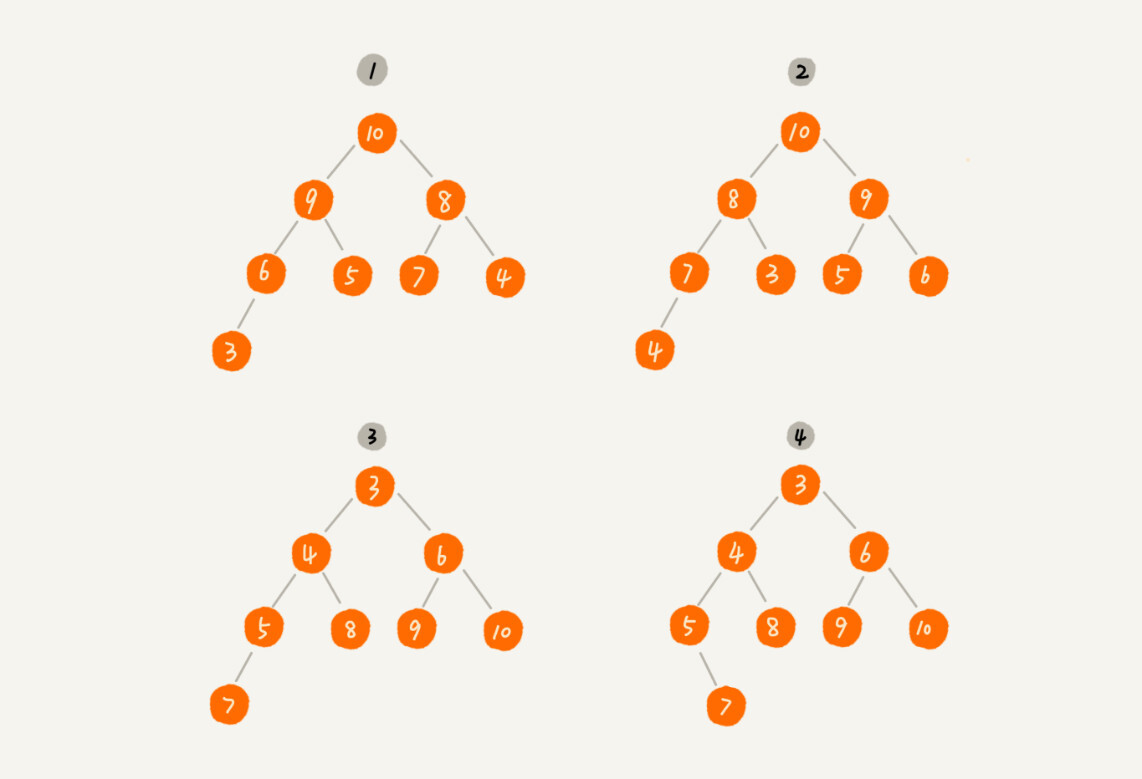
其中第 1 个和第 2 个是大顶堆,第 3 个是小顶堆,第 4 个不是堆。除此之外,从图中还可以看出来,对于同一组数据,我们可以构建多种不同形态的堆。
more >>13讲
13 | 线性排序:如何根据年龄给100万用户数据排序?
桶排序(Bucket sort)
首先,我们来看桶排序。桶排序,顾名思义,会用到“桶”,核心思想是将要排序的数据分到几个有序的桶里,每个桶里的数据再单独进行排序。桶内排完序之后,再把每个桶里的数据按照顺序依次取出,组成的序列就是有序的了。

桶排序的时间复杂度为什么是 O(n) 呢?我们一块儿来分析一下。
如果要排序的数据有 n 个,我们把它们均匀地划分到 m 个桶内,每个桶里就有 k=n/m 个元素。每个桶内部使用快速排序,时间复杂度为 O(k * logk)。m 个桶排序的时间复杂度就是 O(m * k * logk),因为 k=n/m,所以整个桶排序的时间复杂度就是 O(n*log(n/m))。当桶的个数 m 接近数据个数 n 时,log(n/m) 就是一个非常小的常量,这个时候桶排序的时间复杂度接近 O(n)。
more >>限流算法原理及实现
[TOC]
限流的算法有哪些?
本文介绍几种最常用的限流算法:
- 固定窗口计数器;
- 滑动窗口计数器;
- 漏桶;
- 令牌桶。
固定窗口计数器算法
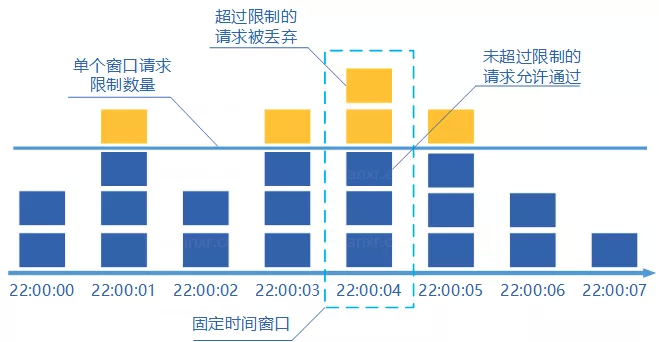
固定窗口计数器算法概念如下:
将时间划分为多个窗口;
在每个窗口内每有一次请求就将计数器加一;
如果计数器超过了限制数量,则本窗口内所有的请求都被丢弃当时间到达下一个窗口时,计数器重置。
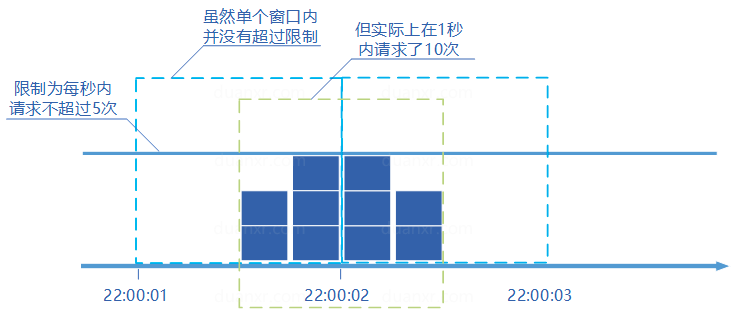
固定窗口计数器是最为简单的算法,但这个算法有时会让通过请求量允许为限制的两倍。考虑如下情况:限制1秒内最多通过5个请求,在第一个窗口的最后半秒内通过了5个请求,第二个窗口的前半秒内又通过了5个请求。这样看来就是在1秒内通过了10个请求。
代码实现:
1 | public class Counter { |
滑动窗口计数器算法
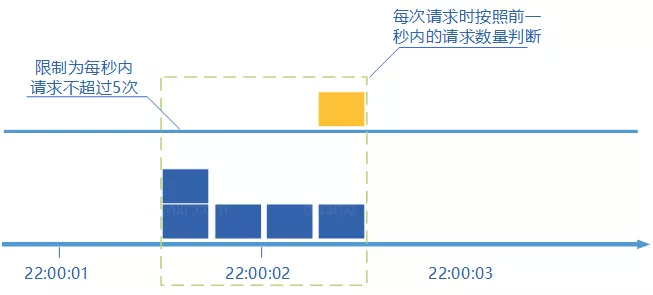
滑动窗口计数器算法概念如下:
- 将时间划分为多个区间;
- 在每个区间内每有一次请求就将计数器加一维持一个时间窗口,占据多个区间;
- 每经过一个区间的时间,则抛弃最老的一个区间,并纳入最新的一个区间;
- 如果当前窗口内区间的请求计数总和超过了限制数量,则本窗口内所有的请求都被丢弃。
滑动窗口计数器是通过将窗口再细分,并且按照时间”滑动”,这种算法避免了固定窗口计数器带来的双倍突发请求,但时间区间的精度越高,算法所需的空间容量就越大。
代码实现:
1.TreeMap版
因为TreeMap没有线程安全版本,所以使用synchronized保证线程安全。
1 | import java.util.Iterator; |
2.ConcurrentLinkedQueue版
因为ConcurrentLinkedQueue已经保证了线程安全,所以无需加锁
1 | import java.util.Iterator; |
漏桶算法
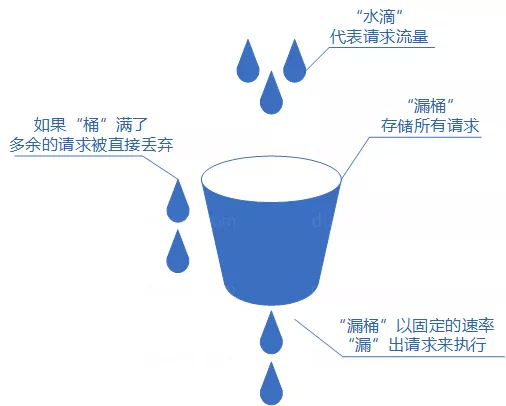
漏桶算法概念如下:
- 将每个请求视作”水滴”放入”漏桶”进行存储;
- “漏桶”以固定速率向外”漏”出请求来执行如果”漏桶”空了则停止”漏水”;
- 如果”漏桶”满了则多余的”水滴”会被直接丢弃。
漏桶算法多使用队列实现,服务的请求会存到队列中,服务的提供方则按照固定的速率从队列中取出请求并执行,过多的请求则放在队列中排队或直接拒绝。
漏桶算法的缺陷也很明显,当短时间内有大量的突发请求时,即便此时服务器没有任何负载,每个请求也都得在队列中等待一段时间才能被响应。
代码实现:
1 | import org.junit.Test; |
令牌桶算法
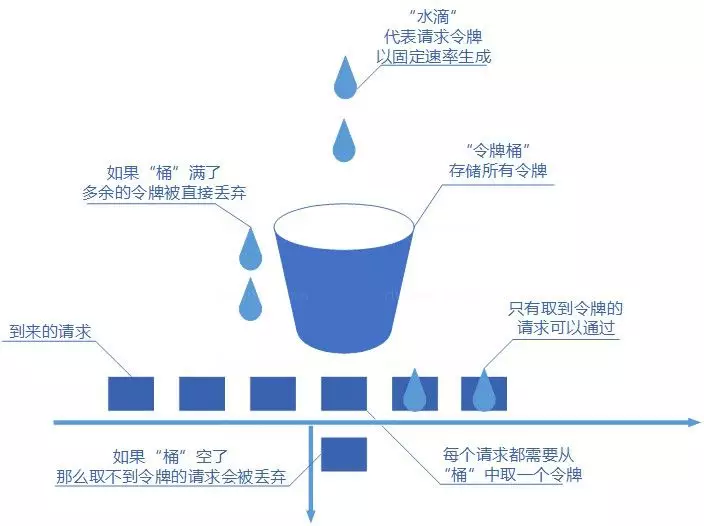
令牌桶算法概念如下:
- 令牌以固定速率生成;
- 生成的令牌放入令牌桶中存放,如果令牌桶满了则多余的令牌会直接丢弃,当请求到达时,会尝试从令牌桶中取令牌,取到了令牌的请求可以执行;
- 如果桶空了,那么尝试取令牌的请求会被直接丢弃。
令牌桶算法既能够将所有的请求平均分布到时间区间内,又能接受服务器能够承受范围内的突发请求,因此是目前使用较为广泛的一种限流算法。
代码实现:
1 | //todo 待补充 |
参考
Kafka面试题
kafka入门
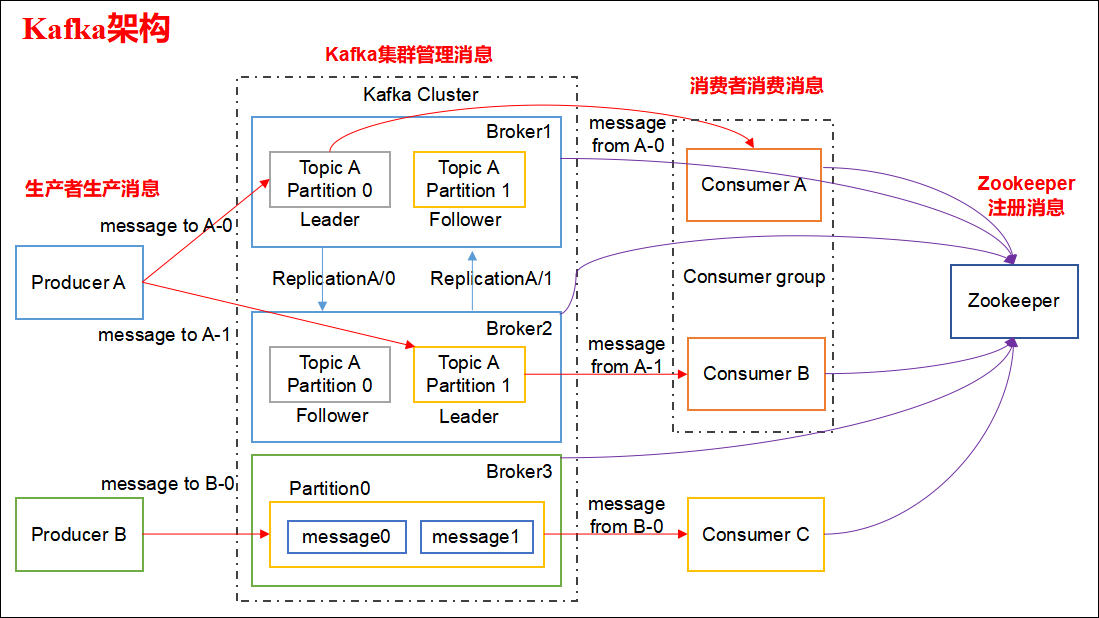
整体架构图
topic
topic可以简单认为是一个队列,每个队列做不同的事情,队列之间相对隔离;每个队列都有不同的名字,这样我们就知道往哪个队列丢数据,也知道从哪个队列拿数据了。我们可以有多个生产者**往同一个队列(topic)丢数据,多个消费者从同一个队列(topic)**拿数据
partition
为了提高每个队列(topic)的吞吐量,kafka会把topic进行分区(Partition)。每个topic包含多个分区。
所以,生产者实际上是往一个topic名为sonder中的分区(Partition)丢数据,消费者实际上是从一个topic名为sonder的分区(Partition)取数据
broker
一台Kafka服务器叫做Broker,Kafka集群就是多台Kafka服务器:
一个topic会分为多个partition,实际上partition会分布在不同的broker中,举个例子:
生产者往一个topic里面丢数据,实际上数据会在partition中,partition会分布在不同的broker(服务器)上。
由此得知:Kafka是天然分布式的。
消费者和消费者组
既然数据是保存在partition中的,那么消费者实际上也是从partition中取数据。
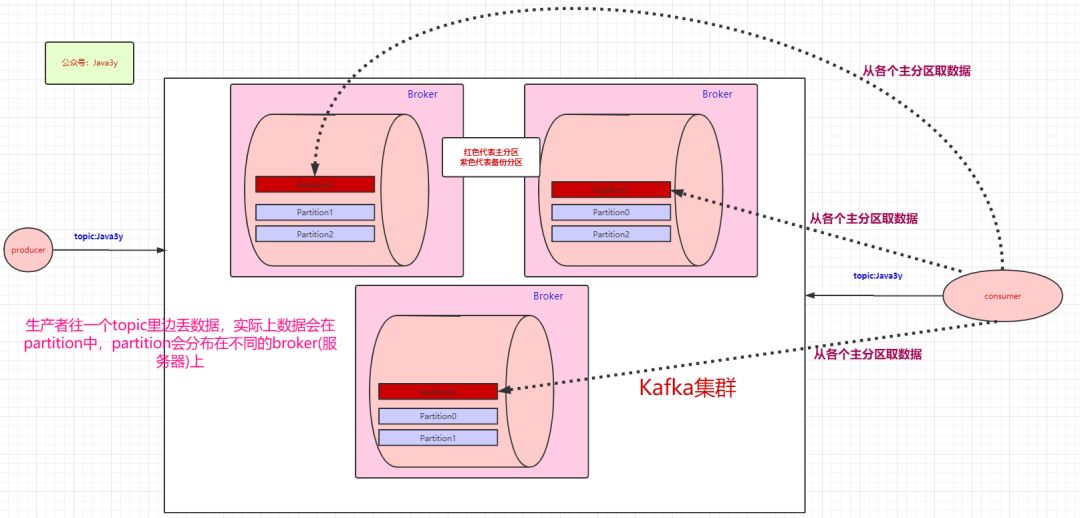
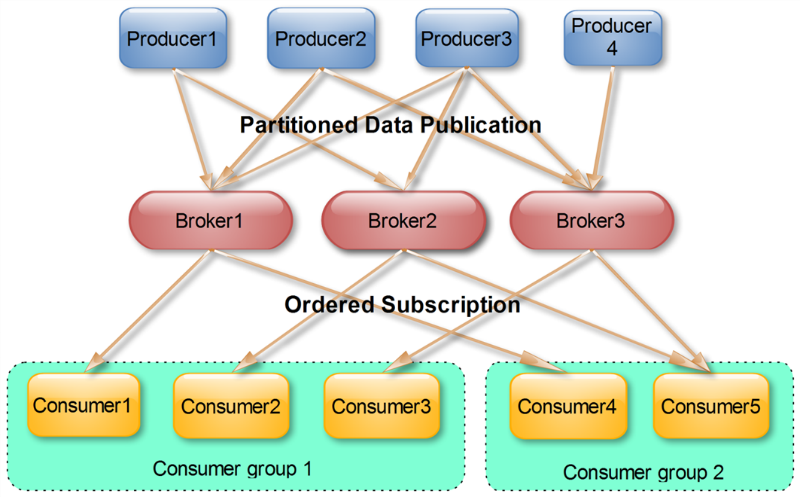
使用 Consumer high level API 时,同一 Topic 的一条消息只能被同一个 Consumer Group 内的一个 Consumer 消费,但多个 Consumer Group 可同时消费这一消息。
这是 Kafka 用来实现一个 Topic 消息的广播(发给所有的 Consumer)和单播(发给某一个 Consumer)的手段。一个 Topic 可以对应多个 Consumer Group。如果需要实现广播,只要每个 Consumer 有一个独立的 Group 就可以了。要实现单播只要所有的 Consumer 在同一个 Group 里。用 Consumer Group 还可以将 Consumer 进行自由的分组而不需要多次发送消息到不同的 Topic。
多个消费者组成一个消费者组,每个消费者组之间相互独立。同一个消费者组中的不同消费者不能同时消费同一个分区的数据。但不同的消费者组可以消费相同的分区的数据(广播消费)。
每个消费者组唯一对应一个topic,一个topic下面可能有多个消费者组,这样就实现了广播消费。
注意:如果消费者不指定消费者组,那么将会使用默认的消费者组,每个topic都有一个默认消费者组。
关于消费者数量,要注意几点:
- 如果消费者组中的某个消费者挂了,那么其中一个消费者可能就要消费两个partition了
- 如果只有三个partition,而消费者组有4个消费者,那么一个消费者会空闲(一个分区不会被两个消费者同时消费)
- 如果多加入一个消费者组,无论是新增的消费者组还是原本的消费者组,都能消费topic的全部数据。(消费者组之间从逻辑上它们是独立的)
高可用
Kafka分区如果出现故障怎么办?
现在我们已经知道了往topic里边丢数据,实际上这些数据会分到不同的partition上,这些partition存在不同的broker上。分布式肯定会带来问题:“万一其中一台broker(Kafka服务器)出现网络抖动或者挂了,怎么办?”
Kafka是这样做的:我们数据存在不同的partition上,那kafka就把这些partition做备份(replica)。比如,现在我们有三个partition,分别存在三台broker上。每个partition都会备份,这些备份散落在不同的broker上。
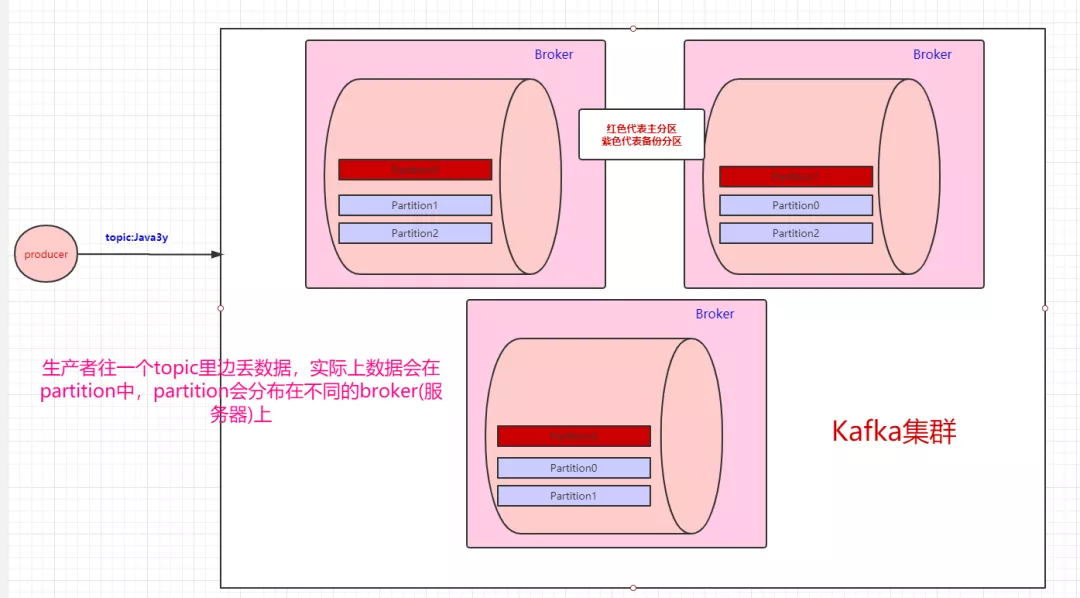
红色块的partition代表的是主分区,紫色的partition块代表的是备份分区。生产者往topic丢数据,是与主分区交互,消费者消费topic的数据,也是与主分区交互。
备份分区仅仅用作于备份,不做读写。如果某个Broker挂了,那就会选举出其他Broker的partition来作为主分区,这就实现了高可用。
ISR(in-sync-replica)机制
可靠性
Kafka消息可靠性是如何保证的?
Acks机制:
- 0:不进行消息接收是否成功的确认(默认值),会丢失数据。
- 1:当Leader副本接收成功后,返回接收成功确认信息,主备切换可能会丢失数据。
- -1(all):当Leader和Follower副本都接收成功后,返回接收成功的确认信息。
消息投递语义
https://www.cnblogs.com/luxiaoxun/p/13048474.html
消息投递语义有三种:
At most once:最多一次,消息可能丢失,但不会重复
At least once:最少一次,消息不会丢失,可能会重复
Exactly once:有且只有一次,消息不会丢失或重复,只会消费一次(0.11版本实现,仅限于下游也是kafka)
幂等:partition内部的exactly-once顺序语义
幂等操作,是指可以执行多次,而不会产生与仅执行一次不同结果的操作,Producer的send操作现在是幂等的。在任何导致producer重试的情况下,相同的消息,如果被producer发送多次,也只会被写入Kafka一次。要打开此功能,并让所有partition获得exactly-once delivery、无数据丢失和in-order语义,需要修改broker的配置:enable.idempotence = true。
这个功能如何工作?它的工作方式类似于TCP:发送到Kafka的每批消息将包含一个序列号,该序列号用于重复数据的删除。与TCP不同,TCP只能在transient in-memory中提供保证。序列号将被持久化存储topic中,因此即使leader replica失败,接管的任何其他broker也将能感知到消息是否重复。
这种机制的开销相当低:它只是在每批消息中添加了几个额外字段:
- PID,在Producer初始化时分配,作为每个Producer会话的唯一标识;
- 序列号(sequence number),Producer发送的每条消息(更准确地说是每一个消息批次,即ProducerBatch)都会带有此序列号,从0开始单调递增。Broker根据它来判断写入的消息是否可接受。
事务机制:跨partition的原子性写操作
https://www.cnblogs.com/luxiaoxun/p/13048474.html
高性能
为什么用kafka不用本地队列
高吞吐
消息持久化
分布式易拓展
kafka为什么这么快
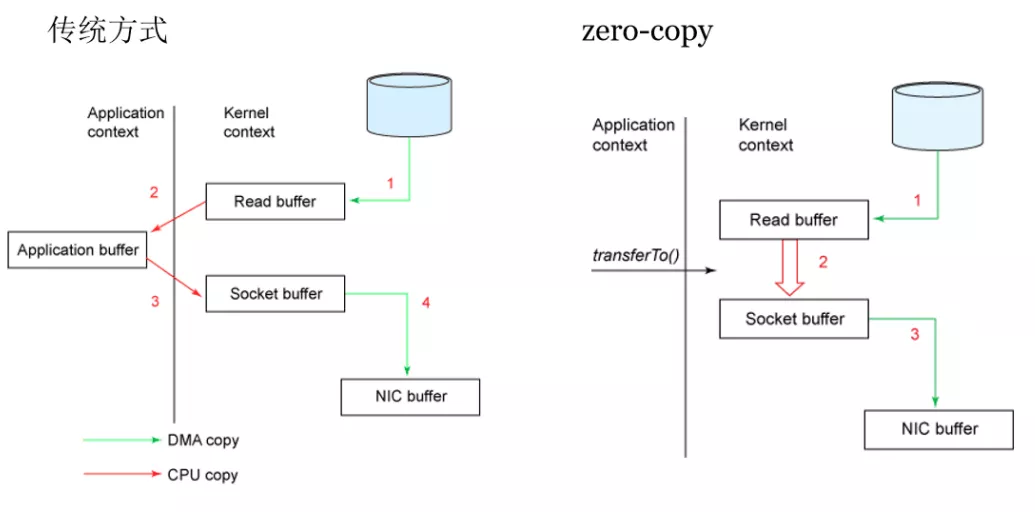
Kafka速度的秘诀在于,它把所有的消息都变成一个批量的文件,并且进行合理的批量压缩,减少网络IO损耗,通过mmap提高I/O速度,写入数据的时候由于单个Partion是末尾添加所以速度最优;读取数据的时候配合sendfile直接暴力输出。
具体分写入和读取两个方面:
写入:
- 使用顺序写入
- Memory Mapped Files
读取:
- 基于sendfile实现Zero Copy
- 批量压缩
什么是零拷贝?
五月第二周
数据结构与算法之美每周打卡 2021.05.17-2021.05.23
437. 路径总和 III
给定一个二叉树,它的每个结点都存放着一个整数值。
找出路径和等于给定数值的路径总数。
路径不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
二叉树不超过1000个节点,且节点数值范围是 [-1000000,1000000] 的整数。
示例:
1 | root = [10,5,-3,3,2,null,11,3,-2,null,1], sum = 8 |
代码
1 |
889. 根据前序和后序遍历构造二叉树
难度中等165
返回与给定的前序和后序遍历匹配的任何二叉树。
pre 和 post 遍历中的值是不同的正整数。
示例:
1 | 输入:pre = [1,2,4,5,3,6,7], post = [4,5,2,6,7,3,1] |
提示:
1 <= pre.length == post.length <= 30pre[]和post[]都是1, 2, ..., pre.length的排列- 每个输入保证至少有一个答案。如果有多个答案,可以返回其中一个。
代码
1 |
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia-plus根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true
nothing here