
蚂蚁国际
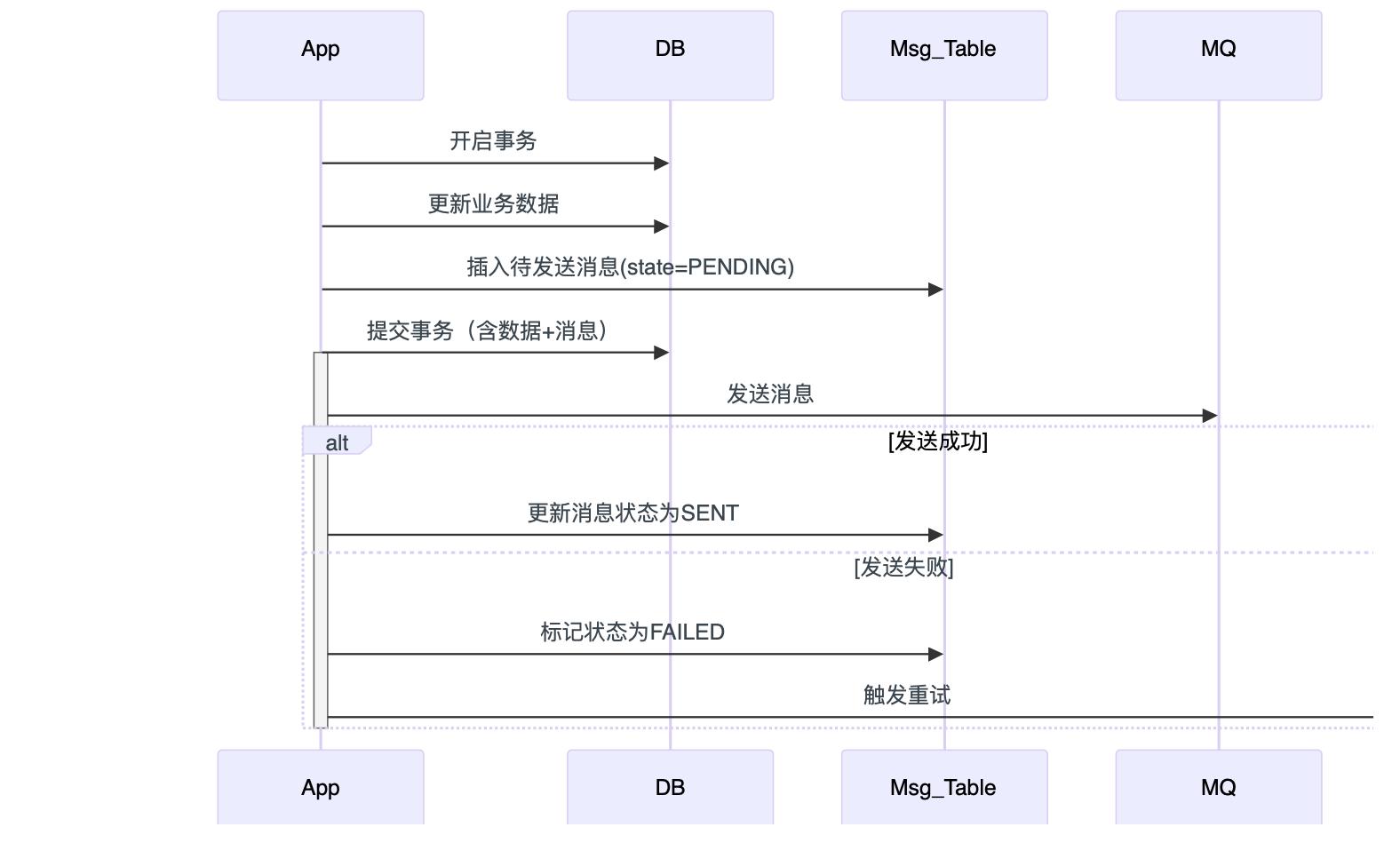
如何保证数据库事务提交和发消息之间的一致性,避免出现消息发出失败导致数据跟消息不同步的问题
通常采用本地消息表或事务消息机制。
本地消息表方案:
- 在数据库操作的同一事务下,先写入业务数据,再插入一条一条待发送的消息到本地消息表。只有事务提交成功,消息才正式入库;
- 异步任务根据消息表轮询发送消息,并记录发送状态,如果投递失败,则进行重试,直至投递成功。
- 消息消费与幂等处理:下游服务在消费消息时需支持幂性,避免重复处理带来数据的不一致性。
- 状态监控与告警:通过状态字段和定时检检测机制,若消息长时间未投递成功,则触发告警或人工干预。
事务消息(如MQ支持的二阶段提交):将消息投递与数据库事务结合,如使用阿里MQ、RocketMQ的事务消息,业务操作与消息发送联合提交,仅当两者均成功才算完成。
补偿机制:通过异步定时任务扫描消息表,补发未送达或异常状态的消息,确保不因短暂故障丢失数据。
消息发送是放在事务里面还是事务外面?能讲讲理由和考虑吗?
消息一般放在本地事务提交之后,即“事务外”发送。原因是如果消息放在事务内,事务提交前即发送则一旦事务回滚,消息已不可靠的发出,会出现数据与消息同步风险。事务外发送则先提交则先提交数据库,可以通过补偿机制(如消息重试、失败消息表、DeadLetterQueue、人工兜底)保障后续一致性。
介绍下事务消息的原理,如何保证数据库事务与消息的一致性的?
事务消息在第二阶段提交时,消息队列的commit操作失败,这个消息是否会一直处于半成功状态(half process)状态
不会
- Broker内置事务回查线程,默认每30秒扫描半消息队列(
RMQ_SYS_TRANS_HALF_TOPIC) - 发现未Commit的消息 → 主动回调生产者实现的
checkLocalTransaction()方法
1
2
3
4// Broker配置示例(broker.conf)
transactionCheckInterval=30000 // 回查间隔(ms)
transactionTimeOut=60000 // 消息超时时间(ms)
transactionCheckMaxCount=5 // 最大回查次数消息生命周期兜底
状态 处理机制 滞留超过60秒 首次触发回查 连续5次回查无果 自动视为失败 → 移至死信队列 消息存储超7天(默认) Broker物理删除 - Broker内置事务回查线程,默认每30秒扫描半消息队列(
事务消息:能梳理一下从事务开启、发送消息到事务结束,整个流程的具体每一步动作是什么吗?
分为消息预发送、事务执行、事务提交确认三个阶段,以保证数据库操作与消息发送的一致性
- Producer发送一条“半消息”(Half Message),消息队列记录该消息但不会立即投递给消费者
- 执行业务操作:Producer本地开启事务,进行如订单创建等操作;如果数据库操作出现异常,则回滚并告知消息队列取消“半消息”
- 消费端执行:下游系统收到消息后根据实际业务进行处理,并可以通过幂等或补偿机制确保处理可靠。
- 消息队列通常有超时与回查机制,避免“半消息”长期滞留影响下游
用过哪些分布式事务的中间件,介绍下他们的原理
除订单、支付等数据一致性要求高的场景,一般采用最终一致性方案
RocketMQ
两阶段提交 2PC
三阶段提交 3PC
Seata
分布式事务中间件Seata的原理
分库分表,设计一个订单表,根据什么维度来分库分表
最常见通过用户ID、业务单号、时间等。
如果是基于user ID做订单表分库分表的情况下,如果需要查某个商户的全部交易数据,怎么实现
每条交易数据冗余记录商家ID字段,并为商家ID建立二级索引
分库分表如何设计
如何保证分布式ID不会出现重复,从而保证唯一性
MySql的乐观锁与悲观锁,如何实现的?
悲观锁:
SELECT * FROM table WHERE id = 1 FOR UPDATE;乐观锁:
UPDATE table SET name='xxx', version=${version}+1 WHERE id = 1 AND version = ${version}介绍下Redis分布式锁,redis的set跟setNX有什么区别
- SetNX (SET if Not eXists) 是旧命令,不能同时设置过期时间,需要额外使用EXPIRE来设置时间;而这2个命令不是原子性的!如果在执行完SetNX后、执行EXPIRE前系统崩溃了,那么锁永远不会释放
- Set是新命令:可以使用一条原子命令设置键值并指定过期时间,完美的解决了SetNX+EXPIRE非原子性的问题。
除了redis,还有哪些可以作为分布式锁
ZooKeeper (ZK):
- 实现: 利用其临时有序节点。所有客户端尝试在指定目录下创建临时有序节点(如
lock-0000000001)。客户端检查自己创建的节点是否是当前目录下序号最小的节点,如果是,则获得锁;如果不是,则向序号比自己小的上一个节点注册Watcher监听其删除事件(被动等待锁释放通知)。持有锁的客户端完成业务后主动删除自己创建的节点(锁自动释放,因为它是临时节点)。释放锁会触发监听者的回调。 - 优势: 强一致性(CP模型),原生有序节点实现公平锁,临时节点避免死锁,Watch机制实现阻塞等待。
- 劣势: 性能低于Redis(网络通信和ZK节点操作较重),需要额外维护ZK集群。
etcd:
- 实现: 利用其
Lease(租约)机制和键的Revision(全局修订版号)。客户端创建一个Lease(指定TTL),然后尝试往一个指定键下写入数据(存储唯一标识),并关联这个Lease(lease_id)并设置prev_kv=true(类似CAS)。如果写入成功(表示key不存在或版本匹配),则获得锁。Lease会由etcd在TTL到期后自动删除关联的键值对释放锁(防死锁)。客户端可以通过KeepAlive续租维持锁。判断是否获取锁是通过Revision实现的。 - 优势: 提供强一致性(基于Raft协议),高可用(通常部署集群),Lease机制天然解决锁超时释放问题。
- 劣势: 部署和配置比Redis略复杂,相对较新一些。
- 实现: 利用其临时有序节点。所有客户端尝试在指定目录下创建临时有序节点(如
对比下redis分布式锁跟zookeeper分布式锁
redis:AP,实现简单,非公平锁;极端情况会出现主从不一致的问题,锁未同步导致丢失,导致多个请求拿到锁。
zookeeper:强一致性(CP模型),原生有序节点实现公平锁,临时节点避免死锁,Watch机制实现阻塞等待(不需要不断重复尝试获取锁)
Redlock算法?
滴滴
HashMap JDK1.7跟1.8的区别
特性 JDK 1.7 JDK 1.8 数据结构 数组 + 单向链表 数组 + 单向链表/红黑树(链表>8时树化) 插入方式 头插法(可能死循环) 尾插法(避免死循环) 哈希算法 多次位扰动(4次位运算+5次异或) 简化扰动(1次位运算+1次异或) 扩容机制 先扩容再插入 先插入再扩容(判断是否需要扩容) 节点重哈希 全部重新计算索引( indexFor)无需全重算,通过高位判断新位置 核心优化:
- 树化:链表过长时转为红黑树(阈值=8),查询时间复杂度从
O(n)降至O(log n)。 - 尾插法:解决多线程下扩容死循环问题(非线程安全本质未变)。
- 扩容优化:新索引 = 原位置 或 原位置+旧容量(通过
(e.hash & oldCap) == 0判断)。
- 树化:链表过长时转为红黑树(阈值=8),查询时间复杂度从
锁升级过程,分别占用了什么资源
介绍下ThreadLocal,以及有什么问题
线程池的参数,以及流程
参数 说明 corePoolSize核心线程数(即使空闲也保留) maximumPoolSize最大线程数(任务队列满时启用) keepAliveTime非核心线程空闲存活时间 workQueue任务队列(ArrayBlockingQueue等) threadFactory线程创建工厂(可定制线程名等) handler拒绝策略(AbortPolicy、CallerRunsPolicy等) 执行流程:
- 提交任务 → 核心线程未满 → 创建线程执行。
- 核心线程已满 → 任务入队列。
- 队列满且线程数 <
maxPoolSize→ 创建非核心线程执行。 - 线程数 =
maxPoolSize且队列满 → 触发拒绝策略。
拒绝策略示例:
AbortPolicy:抛RejectedExecutionException(默认)。CallerRunsPolicy:由提交任务的线程执行任务。
从业务层和中间件出发(以kafka为例)如何防止消息丢失,以及如何防止消息重复消费
防丢失:消费者关闭自动提交,手动提交offset;异常消息放到死信队列,交给人工处理等
如何保证缓存跟数据库的一致性(延迟双删,或者binlog异步消费更新缓存)
方案 优点 缺点 延迟双删 实现简单 强依赖延迟时间(可能仍有不一致) binlog异步消费 最终一致性强(无业务侵入) 架构复杂(需监听binlog的组件如Canal) 延迟双删步骤:
- 删除缓存
- 更新数据库
- 延迟一定时间(如500ms)后再次删除缓存(清理期间读请求加载的脏数据)
binlog方案:
- 数据库更新 → binlog记录变更。
- Canal监听binlog → 发送MQ → 消费服务更新缓存。
关键点:
- 允许短暂不一致(根据业务容忍度选择方案)。
- 避免”先删缓存再更新DB“的并发问题(旧数据回填)。
- 使用 分布式锁 控制并发读写(仅必要时)。
HashKey
请设计一个高并发的系统,前端后端如何优化
高并发系统设计需从架构、基础设施和代码层优化,确保可扩展性和低延迟:
- 前端优化:
- CDN(内容分发网络):缓存静态资源(如图片、CSS、JS),分散用户请求到边缘节点,减少源服务器压力。
- 异步加载:使用AJAX或WebSockets实现部分页面刷新,减少全页请求。
- 资源压缩:压缩图片(WebP格式)、JS/CSS文件,减少传输大小。
- 浏览器缓存:设置HTTP缓存头(如Cache-Control),复用静态资源。
- 懒加载:延迟非核心资源(如滚动时加载图片),提高首屏速度。
- 后端优化:
- 负载均衡:使用Nginx或HAProxy分发请求到多个应用服务器,避免单点故障。支持动态扩缩容。
- 服务拆分:微服务架构(如Spring Cloud),分离功能模块(如用户服务、支付服务),降低耦合。
- 缓存策略:
- Redis/Memcached缓存热点数据(如用户会话、商品信息)。
- 本地缓存(如Caffeine)减少远程调用。
- 数据库优化:
- 分库分表:水平分片(如按用户ID哈希)处理大数据表;垂直分表拆分大字段。
- 读写分离:主库写,多个从库读,配合复制(如MySQL Replication)。
- 异步处理:消息队列(如Kafka或RabbitMQ)解耦耗时操作(如日志、邮件发送),提高响应速度。
- 连接池与线程池:使用HikariCP数据库连接池、Java ThreadPoolExecutor,复用资源,避免创建开销。
- 地理分布:多机房部署,结合DNS或全局负载均衡(如AWS Global Accelerator),减少延迟。
- 容错机制:熔断(如Hystrix)、降级(非核心功能兜底)、自动扩缩(如Kubernetes)。
- 监控与测试:
- 监控工具:Prometheus + Grafana跟踪QPS、延迟。
- 压测:使用JMeter或k6模拟高负载,验证优化效果。
关键点:优化需结合实际业务(如电商系统侧重缓存,金融系统侧重分布式事务),基准是RPS(每秒请求数)提升和P99延迟降低。
- 前端优化:
Kafka是如何保证顺序性
Kafka通过分区(Partition)机制保证消息顺序性:
- 分区内有序:每个Partition是一个FIFO队列,消息写入和消费严格有序。
- Producer端:消息发送时指定key(如订单ID),相同key通过哈希函数路由到同一Partition,确保同key消息顺序。
- Consumer端:每个Partition由一个Consumer实例消费,保证Partition内顺序处理;Consumer Group协调多Consumer并行,但每个Partition仅被一个Consumer占用。
示例:订单创建、支付、完成事件,按订单ID分发到同一Partition,确保处理顺序。
注意:全局顺序需所有消息进一个Partition,但会牺牲并发,故通常仅关键数据保证顺序。
Kafka如何保证消息不丢失的
消息不丢失需Producer、Broker、Consumer三端保障:
- Producer端:
acks=all:Producer需所有ISR(In-Sync Replica)副本确认写入成功。- 重试机制:
retries=Integer.MAX_VALUE,自动重试发送失败消息。 - 幂等性:
enable.idempotence=true避免网络重试时消息重复。
- Broker端:
- 副本机制:Topic设置
replication.factor >= 2,数据多节点冗余。 - 持久化:消息写入磁盘(日志文件),避免内存丢失。
- ISR机制:Leader副本仅同步给ISR列表中的Follower,确保多数副本一致。
- 副本机制:Topic设置
- Consumer端:
- 手动提交Offset:
enable.auto.commit=false,业务处理成功后显式commit(),避免未处理即提交。 - Exactly-Once语义:事务API(Kafka >=0.11)保障消费原子性。
风险点:Broker宕机需快速恢复(如Kafka Controller选举),分区重平衡可能导致短暂丢失,可结合min.insync.replicas配置提升安全性。
- 手动提交Offset:
- Producer端:
【线上】kafka如果遇到大量消息堆积,怎么办?
短期应急:
- 扩增Consumer Group实例数,提升并行度(需保证分区数>=Consumer实例数,多余的消费者无效)
- 写一个分发的程序,将topic均匀分发到临时topic
- 同时起N台消费者,消费不同的临时Topic
长期优化:
提高消费并行度:批量消费,一次拉取更多的消息,多线程消费;Consumer内缓存消息分批处理,减少网络IO。
架构调整:重试队列,异常消息写入死信队列,重试或人工处理,避免阻塞主流程;检查分区数据倾斜,调整key哈希逻辑。
高并发修改一个变量或多个变量,如何实现
单机环境:synchronized、ReentrantLock、volatile变量确保可见性
分布式环境:redis SetNX分布式锁;一致性协议,用Raft/Paxoss(如etcd),但开销大
优化策略:
减少竞争
- 乐观锁
- 分治:变量分片(如用户ID哈希到不同锁实例)
无状态设计:转换变量为事件源(Event Sourcing),通过消息队列串行处理。
Websocket跟Http的区别,Websocket如何实现监听某一个topic
特性 HTTP WebSocket 协议模型 请求-响应(半双工) 双向通信(全双工) 连接方式 短连接(无状态) 长连接(持握后保持) 通信模式 客户端主动发起 服务端可主动推送 开销 HTTP头大(每请求冗余信息) 初始握手后帧头小 使用场景 API调用、网页加载 实时应用(聊天、游戏、监控) WebSocket协议本身无Topic概念,需应用层实现:
连接时订阅:客户端通过握手后的消息指定Topic,如JSON消息:
1
{"action": "subscribe", "topic": "stockUpdates"}
服务端映射:服务端维护连接池(如
Map<topic, List<WebSocketSession>>),根据Topic广播消息。框架支持:Spring WebSocket的
@SubscribeMapping("/topic/stockUpdates"),STOMP协议内置Topic路由。
核心:Topic是逻辑分区,由后端代码和客户端协议约定。
redis分布式锁,如果业务超时,阻塞别的业务怎么办
setNX添加EXPIRE过期时间,如果业务没处理完,要么自动续期,要么强制timeout,释放锁
如果业务没处理完,redis分布式锁过期了怎么办
守护线程定期续期(Redission的看门狗机制),超时钱刷新TTL
Redis WATCH命令
Redis WATCH用于乐观锁机制,确保事务期间键不被修改
机制:
WATCH key监控键,启动事务(MULTI)。- 执行事务命令(EXEC)前,若键被其他客户端修改,事务失败(返回nil)。
- 基于CAS(Compare and Swap),无锁并发控制。
用例:如银行转账,保证余额一致:
1
2
3
4
5WATCH balance:user1 balance:user2
MULTI
DECRBY balance:user1 100
INCRBY balance:user2 100
EXEC # 若balance在WATCH后变化,EXEC失败限制:
- 非原子事务:失败需重试(循环逻辑),增加代码复杂度。
- 性能:监控多键时,冲突可能频繁。
替代:高并发场景更适合分布式锁或数据库事务。
如何在1s中处理100w条交易数据
架构设计:
数据分片:哈希分片(按照用户ID)到多节点,并行处理(100个节点各处理1w条)
单个节点的优化:
批量操作:批量插入数据库(Batch INSERT)、批量提交(如Kafka batch.size)
异步IO:非阻塞读写(如NIO)、线程池处理
数据库优化:向量化写入(如ClickHouse)、列式存储
估算:
100w/1s/1000节点,每个节点处理1000TPS
假设单节点,单核处理100TPS,需10个线程。
线程池的参数,worker类里面的属性,线程什么时候会被回收,返回什么属性会被回收
Worker类属性:内部类Worker(实现Runnable)管理线程:
thread:持有的线程实例(通过Factory创建)。firstTask:初始任务(可为null)。completedTasks:完成任务计数。
什么条件下线程会被回收:
当getTask()方法返回null的时候,线程将会被回收;因为getTask()方法是被runWorker方法调用,在runWorker方法中,如果getTask()返回null,则线程会自动销毁:processWorkerExit
getTask()方法注释:Returns: task, or null if the worker must exit, in which case workerCount is decremented
- 线程在
workQueue.poll(keepAliveTime, ...)超时后返回null - 线程退出
runWorker()循环,结束run()方法。 - 线程对象失去引用,由JVM垃圾回收。
MySql 5亿数据如何优化,加速查询
考虑ES
redis几种数据结构
redis 2个100万数据的set求交集,大概花费多久时间
预计5-30ms(不考虑网络传输耗时),百万级别哈希查找在内存中极快。
SINTER set1 set2命令,Set底层为哈希表结构,求交集时Redis采用双重遍历+哈希查找
- 先找到最小的集合(若大小接近则任选其一)
- 遍历最小集合的每个元素,在其他集合中哈希查找(O(1) 操作),如果再任意一个其他集合中没有找到,直接跳到下一个元素
- 时间复杂度近似 O(M*N)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28// Redis 7.0 源码片段 (t_set.c)
void sinterGenericCommand(client *c, robj **setkeys, unsigned long setnum) {
// 步骤1:找出最小集合
robj *minset = NULL;
long minsize = LONG_MAX;
for (j = 0; j < setnum; j++) {
if (setTypeSize(sets[j]) < minsize) {
minset = sets[j];
minsize = setTypeSize(sets[j]);
}
}
// 步骤2:遍历最小集合元素
setTypeIterator *si = setTypeInitIterator(minset);
while ((encoding = setTypeNext(si, &curobj)) != -1) {
int ismember = 1;
// 检查元素是否存在于所有其他集合
for (j = 0; j < setnum; j++) {
if (sets[j] == minset) continue;
if (!setTypeIsMember(sets[j], curobj)) { // 哈希查找 O(1)
ismember = 0;
break;
}
}
if (ismember) addReplyBulk(c, curobj);
}
setTypeReleaseIterator(si);
}

